نظر
نظر
آیا شما ترجیح می دهید دانشمند داده NLP یا رایانه باشید؟
نگاهی دقیق تر به این نقش های معروف Data Scientist.
 عکس توسط JESHOOTS.COM در Unsplash [1].
عکس توسط JESHOOTS.COM در Unsplash [1]. فهرست مطالب
< oli> مقدمهمقدمه
هنگام درخواست موقعیت شغلی به عنوان دانشمند داده ، ممکن است انواع مهارت های مورد نیاز را در قسمت شرح شغل مشاهده کنید. شما پایین بروید و سپس ببینید تحصیلات مورد نیاز بین پست ها متفاوت است. مهمتر از همه ، شما یک نمای کلی می بینید که نقش را خلاصه می کند ، و اگرچه عنوان موقعیت یکسان است ، بخش به طور قابل توجهی متفاوت است. این تغییر به دلیل انواع مختلف موقعیت های علم داده موجود است. با این حال ، من متوجه شده ام که این نقش ها نام جدیدی به خود می گیرند زیرا شرکت ها تخصص خود را در علم داده درک می کنند. این دو شاخه محبوب علم داده عبارتند از پردازش زبان طبیعی (NLP) و دید رایانه ای. بسته به شرکتی که در نهایت قصد دارید در آن کار کنید یا در حال حاضر در آن کار می کنید ، برخی از موقعیت ها همچنان عنوان Data Science نامیده می شوند ، اما بر NLP یا Computer Vision تمرکز دارند ، در حالی که برخی از موقعیت ها به طور کلی علم داده است. من هم NLP و هم Computer Vision را برجسته می کنم تا بتوانید اطلاعات بیشتری در مورد معنای بودن هر کدام ، همراه با حقوق مورد انتظار ، و اینکه کدام نقش در نهایت تخصص بهتری برای شما است ، بیابید.
داده ها علم
علم داده یک اصطلاح بسیار گسترده است که اغلب بین مردم ، به ویژه در زمینه تکنولوژی مورد مناقشه است. دانشمندان داده فعلی می توانند نسبت به آنچه فکر می کنند علم داده بر اساس آنچه در اولین شغل خود تجربه کرده اند تعصب داشته باشند ، اما بعداً متوجه خواهند شد که علم داده در واقع یک اصطلاح کلی برای چندین رشته است. این رشته ها شامل پردازش زبان طبیعی ، دید رایانه ای ، یادگیری ماشین ، آمار ، ریاضیات ، برنامه نویسی ، تجزیه و تحلیل داده ها ، مدیریت محصول و هوش تجاری است. این واقعاً به شما و شرکتی که در آن کار می کنید بستگی دارد که تصمیم بگیرند از چه مسیر خاصی می خواهید بروید یا شاید در همه این جنبه ها کلی گرا باشید. از مزایای تخصص در NLP یا Computer Vision این است که می دانید در چه زمینه ای هستید و می توانید بر یادگیری و بهبود مهارت های خاص مورد نیاز هر موقعیت متمرکز شوید.
پردازش زبان طبیعی
گاهی از دانشمندان متخصص در NLP به عنوان مهندس NLP نیز یاد می شود. این تخصص بر زبان طبیعی انسانها و چگونگی مشارکت رایانه ها در هضم این ورودی بدون ساختار و سپس خروجی معنای ساختار یافته و مفید متمرکز است. در حالی که تعاریف و مثال های بی شماری از این نوع علم داده وجود دارد ، من می خواستم تجربه شخصی و در عین حال حرفه ای خود را با NLP ارائه دهم. من با سه نوع پروژه NLP کار کرده ام. این سه پروژه شامل موارد زیر است: به سایر اشکال NLP نیز. همه آنها ابزارها و کد مشابهی را برای ایجاد خروجی های مفید به اشتراک می گذارند. من به طور خاص بیشترین کار را با NLP در زبان برنامه نویسی پایتون انجام داده ام.
تجزیه و تحلیل احساسات - این فرم ازNLP بر خلق و خو ، احساسات ، قطبیت و موضوعیت یک متن معطوف می شود. یک جریان معمول کار برای تجزیه و تحلیل احساسات این است که داده های خود را جمع آوری کرده ، پیش پردازش کنید و سپس آن را نشانه گذاری کنید. اساساً ، در این مرحله ، شما هر کلمه ای را که در حال تجزیه و تحلیل ، تمیز کردن و حذف آن هستید خواهید داشت تا کلمات برچسب گذاری شوند. این قسمت بعدی معمولاً به عنوان برچسب گذاری POS یا Part-of-Speech شناخته می شود. هنگامی که نوع کلمات خود را مانند صفت ها ، اسم ها و افعال تعیین کردید ، می توانید به راحتی از عملکرد کتابخانه ای استفاده کنید که نمره قطبی را برای هر متن تعیین می کند. برخی از کتابخانه های NLP احساسی محبوب TextBlob و vaderSentiment هستند. من در اینجا زیاد عمیق نمی شوم ، اما اگر می خواهید مقاله ای در مورد ویژگی های NLP و این دو کتابخانه مشهور نوشته شود ، خوشحال می شوم این کار را انجام دهم (لطفاً در زیر نظر دهید). تجزیه و تحلیل احساسات می تواند به طور گسترده ای توسط اکثر مشاغل استفاده شود. در اینجا چند نمونه از مواردی که می توان تجزیه و تحلیل احساسات را اعمال کرد آورده شده است: بهبود محصول
در اینجا خلاصه ای از تجزیه و تحلیل احساسات آمده است:
جمع آوری داده ها
پیش پردازش
توکن
برچسب POS
نمره دهی
مدلسازی موضوع - این شکل از NLP تحت شاخه ای از یادگیری بدون نظارت است که به شما کمک می کند تا موضوعات اسناد متشکل از متن را بیابید. یکی از رایج ترین روش های یافتن موضوعات در یک سند ، استفاده از LDA یا Latent-Dirichlet-Allocation است. این یک تکنیک است که در نهایت موضوعاتی را که عبارات کلیدی محبوب و مهم را از متن شما خلاصه می کند ، نشان می دهد. در اینجا چند نمونه از مواردی که می توان از مدل سازی موضوعات استفاده کرد آورده شده است:
- ارائه موضوعات جدید از متن
- استفاده از این موضوعات برای تعیین برچسب های یادگیری تحت نظارت
< p> - بینش هایی که از جستجوی دستی بسیار دشوار استدسته بندی متن - این فرم از NLP یک تکنیک یادگیری تحت نظارت است که به طبقه بندی نمونه های جدید داده ها که نیازی به لزوماً فقط متن ندارند ، کمک می کند. اما حاوی مقادیر عددی نیز می باشد. گسترده تر از دو فرم NLP ، می توانید دسته بندی متن را به عنوان یک الگوریتم طبقه بندی معمولی در نظر بگیرید ، جایی که برچسب متن است و برخی از ویژگی ها نیز متن هستند. از همان تکنیک های بالا برای پیش پردازش ، تمیز کردن و استخراج معنی از متن استفاده خواهید کرد. در اینجا چند نمونه از مواردی که می توان طبقه بندی متن را اعمال کرد آورده شده است: p> محبوب ترین بسته پایتون nltk [2] است که مخفف Natural Language Toolkit است. شامل چندین کتابخانه است که در تلاش شما برای حل مشکلات با تکنیک های NLP ضروری هستند.
یک مهندس NLP چقدر درآمد دارد؟
بینایی رایانه ای
من معتقدم که این حوزه از علم داده حتی تخصصی تر از NLP است. Computer Vision به جای داده های عددی یا متنی بر داده های تصویری و تصویری تمرکز می کند. از نظر من ، رایانه چشم انداز خطرات بیشتری دارد زیرا می تواند در آن استفاده شودصنایع بیشتری که لزوماً به بینش وابسته نیستند ، اما نیاز به اقدامات امنیتی و ایمنی دارند تا به کار گرفته شوند. به این فکر کنید که چگونه تجزیه و تحلیل NLP و احساسات برای تجزیه و تحلیل خوشبختی بازبینی افراد مفید بوده است ، این بینش مفید و قدرتمند است ، اما به همان اندازه که بینایی رایانه می تواند مfulثر یا مضر باشد ، مفید نیست. من برخی از انواع Computer Vision را در زیر برجسته می کنم.
تشخیص چهره - هنگامی که تلفن خود را بر می دارید ، به احتمال زیاد یک ویژگی امنیتی دارید که چهره شما را تجزیه و تحلیل می کند تا ببیند آیا واقعاً شما در تلاش برای دسترسی به خود هستید تلفن. یک کتابخانه معروف پایتون که از پروژه هایی برای تشخیص چهره سود می برد ، به درستی به عنوان face_recognition نامیده می شود. تصاویری که با آنها کار می کنید و از صورت تشکیل شده اند به صورت یک ویژگی کدگذاری می شوند. بر اساس ویژگی های مشترک صورت ، می توانید چهره های فردی را با چهره های یکسان یا متفاوت مطابقت دهید (یا ندهید) تا در نهایت صورت را تشخیص دهید.
تشخیص شی - با استفاده از اطلاعات شیء ، این فرم رایانه می تواند در تشخیص اجسام کمک کند. OpenCV یک ابزار محبوب است که توسط برنامه نویسان و دانشمندان داده که مایل به تمرکز بر تشخیص اشیا هستند ، مورد استفاده قرار می گیرد.
شما می توانید نمونه هایی از دید کامپیوتر را در موارد زیر پیدا کنید:
- تشخیص تصویر
- شناسه چهره iPhone
- برچسب گذاری در فیس بوک
- تشخیص عابران پیاده و خودروهای تسلا
یک مهندس بینایی کامپیوتر چقدر درآمد دارد؟
در حالی که هر دو این حقوق زیاد است ، من شخصاً از آگهی های استخدام دیده ام که نه تنها مهندسان بینایی کامپیوتر بیش از متوسط حقوق گزارش شده ، بلکه مهندسان NLP نیز درآمد دارند. از آنجا که این دو نقش در علم داده بیش از پیش تخصصی می شوند ، معتقدم به همین دلیل می توانید انتظار داشته باشید که حقوق بالاتری داشته باشید.
خلاصه
 عکس توسط Annie Spratt در Unsplash [5].
عکس توسط Annie Spratt در Unsplash [5]. اکثر دانشمندان داده احتمالاً نوعی از NLP یا Computer Vision را مطالعه کرده اند ، خواه از دانشگاه باشد یا از آموزش آنلاین. هر دوی این نقش های تخصصی در علم داده بسیار مورد احترام هستند و می توانند به صنایع بی شماری سود ببرند. هنگام پاسخ به این س ‘ال که "ترجیح می دهید مهندس NLP باشید یا مهندس بینایی کامپیوتر؟" در نهایت به ترجیحات و اهداف شغلی شما بستگی دارد. به این فکر کنید که دوست دارید در چه نوع پروژه هایی کار کنید ، در کدام صنعت می خواهید کار کنید و دوست دارید با کدام شرکت مرتبط باشید. هر دوی این موضوعات در علم داده می تواند نتایج بسیار بالایی از کار شما به همراه داشته باشد ، بنابراین هر یک به شما یک تجربه انگیزشی می دهد.
امیدوارم این مقاله برای شما جالب و مفید بوده باشد. با خیال راحت در زیر تجربه خود به عنوان یک دانشمند داده عمومی ، مهندس NLP یا مهندس بینایی رایانه کامنت بگذارید.
از شما برای خواندن متشکرم!
منابع
[ 1] عکس توسط JESHOOTS.COM در Unsplash ، (2018)
[2] پروژه NLTK ، مجموعه ابزار زبان طبیعی ، (2020)
[3] Glassdoor، Inc.، NLP Engineer حقوق و دستمزد ، (2008–2020)
[4] Glassdoor، Inc.، Computer Vision Engineers Salaries، (2008–2020)
[5] عکس توسط Annie Spratt در Unsplash ، ( 2020)
Candid: یک زبان رایج برای رابط های کاربردی در رایانه اینترنتی
Candid: یک زبان رایج برای رابط های کاربردی در رایانه اینترنتی
معرفی Candid ، یک زبان توصیف رابط کاربری جدید برای رایانه اینترنتی ، که کد میزبان را قادر می سازد تا یکپارچه ادغام شود
 ما ابزارهایی را برای ایجاد خودکار UI و انجام آزمایش تصادفی بر اساس فایل شرح خدمات ایجاد کردیم. < p> همانطور که بنیاد DFINITY برای راه اندازی اینترنت به ریشه های آزاد و باز خود با راه اندازی رایانه اینترنتی فعالیت می کند ، اولین شبکه بلاک چین با سرعت وب با ظرفیت محاسباتی نامحدود ، افزایش تجربه توسعه دهندگان و ارائه گزینه های بیشتر ، یک تمرکز ثابت است. رایانه اینترنتی میزبان قوطی های نرم افزاری است ، تکامل قراردادهای هوشمند سنتی که می توانند مقیاس پذیر شوند ، که شامل کد بایتی WebAssembly با صفحاتی از حافظه است که کد در آنها اجرا می شود. اینها توسعه دهندگان را قادر می سازد تا برنامه های کاربردی ، سیستم ها و سرویس های اینترنتی سازگار با امنیت ، غیرقابل توقف و استفاده از ویژگی های بلاک چین مانند توکن سازی را ایجاد کنند که به طور مستقیم در اینترنت و نه در زیرساخت های اختصاصی مستقر می شوند.
ما ابزارهایی را برای ایجاد خودکار UI و انجام آزمایش تصادفی بر اساس فایل شرح خدمات ایجاد کردیم. < p> همانطور که بنیاد DFINITY برای راه اندازی اینترنت به ریشه های آزاد و باز خود با راه اندازی رایانه اینترنتی فعالیت می کند ، اولین شبکه بلاک چین با سرعت وب با ظرفیت محاسباتی نامحدود ، افزایش تجربه توسعه دهندگان و ارائه گزینه های بیشتر ، یک تمرکز ثابت است. رایانه اینترنتی میزبان قوطی های نرم افزاری است ، تکامل قراردادهای هوشمند سنتی که می توانند مقیاس پذیر شوند ، که شامل کد بایتی WebAssembly با صفحاتی از حافظه است که کد در آنها اجرا می شود. اینها توسعه دهندگان را قادر می سازد تا برنامه های کاربردی ، سیستم ها و سرویس های اینترنتی سازگار با امنیت ، غیرقابل توقف و استفاده از ویژگی های بلاک چین مانند توکن سازی را ایجاد کنند که به طور مستقیم در اینترنت و نه در زیرساخت های اختصاصی مستقر می شوند. برای حمایت از رشد جهان نرم افزارهای تصویری مجدد در یک بلاک چین عمومی که در آن برنامه های مختلف می توانند مستقیماً با یکدیگر ادغام شوند و خدمات را می توان به راحتی ترکیب و گسترش داد ، تیم زبانهای ما زبان توصیف واسط کاندید (IDL) را توسعه داد ، که به طور مشترک به آنها امکان می دهد ساختن اکوسیستم رایانه اینترنتی برای اتصال کاملاً یکپارچه کد آنها ، حتی اگر به زبانهای مختلف نوشته شده باشد ، که ما مشتاق هستیم امروز با جزئیات بیشتر آن را شرح دهیم.
Candid چیست؟
Candid یک IDL است که به طور خاص برای رایانه اینترنتی ساخته شده است و یک زبان مشترک برای رابط های برنامه برای تسهیل ارتباط بین سرویس های نوشتاری ارائه می دهد. n در زبانهای برنامه نویسی مختلف.
یکی از مزایای کلیدی Candid این است که زبان را می شناسد و قابلیت همکاری بین سرویس ها و قسمت های جلویی را که به زبان های مختلف برنامه نویسی مانند Motoko ، Rust و جاوا اسکریپت ، و سایر موارد. این به توسعه دهندگان اجازه می دهد بدون نگرانی در مورد ارتقاء رابط در سرویس های خارجی ، سرویس هایی را که به یکدیگر متکی هستند ، با خیال راحت و بدون دردسر بسازند. توسعه دهندگان با استفاده از Candid توانایی توصیف رابط عمومی یک سرویس را دارند ، معمولاً در قالب برنامه ای که به عنوان قوطی استفاده می شود. به عنوان یک توسعه دهنده ، می توانید سرویسهای خارجی که در رایانه اینترنتی در حال اجرا هستند را به عنوان فراخوانی تابع ناهمزمان فراخوانی کنید. بدون شکستن کلاینت های موجود-به عنوان مثال ، به این معنی که می توانید با خیال راحت پارامترهای اختیاری جدید را بدون از دست دادن سازگاری برای مشتریان فعلی به سرویس اضافه کنید.
کاندید تا حدودی از IDL های مشابه و زبانهای تعریف داده (DDL) مانند Protobuf ، Thrift و JSON الهام گرفته شده است. اما Candid ترکیبی منحصر به فرد از ویژگی هایی را ارائه می دهد که در این فناوری های دیگر یافت نمی شود:
چگونه از Candid استفاده کنم؟
هدف اصلی Candid اتصال برنامه هایی است که به زبان میزبان نوشته شده اند - به عنوان مثال Motoko ، Rust یا JavaScript - با رایانه اینترنتی. در بیشتر موارد ، مجبور نیستید با داده های برنامه خود به عنوان مقادیر Candid برخورد کنید. در عوض ، شما با یک زبان میزبان مانند جاوا اسکریپت با استفاده از مقادیر آشنا جاوا اسکریپت کار می کنید ، و سپس بر Candid تکیه می کنید تا این مقادیر را به صورت شفاف به قوطی نوشته شده در Rust یا Motoko منتقل کند. قوطی مقادیر را دریافت می کند و آنها را به عنوان مقادیر اصلی Rust یا Motoko در نظر می گیرد.
مواردی وجود دارد که مشاهده مقادیر Candid به طور مستقیم در شکل قابل خواندن برای انسان مفید است-به عنوان مثال ، هنگام ورود به سیستم ، اشکال زدایی ، یا تعامل با یک سرویس در خط فرمان. در این سناریوها ، می توانید از ارائه متنی برای مقادیر Candid استفاده کنید.
Candid یک سیستم قوی تایپ شده با مجموعه ای از انواع است که به طور متعارف بیشتر موارد استفاده را پوشش می دهد (برای مشاهده لیست ، به صفحه SDK ما مراجعه کنید). فلسفه این مجموعه انواع این است که آنها برای توصیف ساختار داده ها کافی هستند تا بتوان اطلاعات را رمزگذاری ، منتقل و رمزگشایی کرد ، اما سعی نمی کنند محدودیت های معنایی فراتر از آن را توصیف کنند. Candid این مجموعه از انواع را پشتیبانی می کند تا امکان ترسیم طبیعی انواع داده ها بر اساس انتخاب های منطقی و متعارف مناسب هر زبان میزبان را فراهم کند ، خواه کد خود را به Motoko ، Rust ، JavaScript یا برخی زبان های دیگر بنویسید.
از انواع کاندید می توان برای توصیف یک سرویس از طریق یک فایل توصیف سرویس Candid (فایل .did) استفاده کرد که می تواند به صورت دستی نوشته شده یا از پیاده سازی سرویس ایجاد شود. به عنوان مثال اگر در Motoko قوطی بنویسید ، کامپایلر هنگام کامپایل برنامه به طور خودکار یک توضیح Candid تولید می کند. در زبان های دیگر ، مانند Rust ، باید توضیحات رابط Candid را به صورت دستی بنویسید. با کمک انواع ، ما ابزارهایی را برای ایجاد خودکار UI و انجام آزمایش تصادفی بر اساس فایل توضیحات سرویس توسعه دادیم.
Candid همچنین برای ارتقاء خدمات مفید است. خدمات در طول زمان تکامل می یابند ؛ آنها روشهای جدیدی به دست می آورند و روشهای موجود داده های بیشتری را برمی گردانند یا انتظار استدلال های اضافی را دارند. معمولاً نویسندگان سرویس می خواهند این کار را بدون شکستن مشتریان موجود انجام دهند. Candid کمک می کند تا خدمات با ایمن سازی قوانین دقیق زیرنوع (در Coq رسمی شده است) تکامل یابد که نشان می دهد نوع سرویس جدید همچنان قادر به برقراری ارتباط با سایر طرف هایی است که از توصیف رابط قبلی استفاده می کنند.
علاقه مند به یادگیری بیشتر؟ در اینجا برخی از مطالب مرتبط با Candid برای شروع…
آموزش ها و منابع کاندیدا
من دارای مدرک علوم کامپیوتر هستم ، حالا چه؟
من دارای مدرک علوم کامپیوتر هستم ، حالا چه؟
مشاغل فارغ التحصیل نیاز به بیش از یک فارغ التحصیل با مدرک مرتبط دارد.
سال 2016 است. من کارشناسی خود را در رشته علوم ریاضی (جریان کامپیوتر) در Stellenbosch به پایان رساندم. دانشگاه در آفریقای جنوبی با وجود اینکه 3 سال طاقت فرسا را صرف ریاضیات ، آمار و ارقام ، نظریه نمودارها ، الگوریتم های پیشرفته ، روش های عددی کرده بودم ...
فیلترهای Snapchat: چگونه دید رایانه چهره شما را تشخیص می دهد

فیلترهای Snapchat: چگونه دید رایانه چهره شما را تشخیص می دهد
علم پشت تشخیص چهره شخصی
در آن لحظات خستگی هنگامی که با فیلترهای Snapchat بازی می کنید - زبان خود را بیرون بیاورید ، ویژگی های خود را غش کنید و نحوه تناسب تاج گل را بیاموزید. دقیقاً روی سر خود هستید - مطمئناً لحظه ای را گذرانده اید که از لحاظ فنی فکر می کنید چه خبر است - چگونه Snapchat موفق می شود چهره شما را با انیمیشن ها مطابقت دهد؟
پس از دو هفته تحقیق آنلاین ، از اینکه بالاخره نیم نگاهی به پشت پرده انداختم ، سپاسگزارم. به نظر می رسد که این محصول نمونه ای از برنامه بینایی رایانه ای است که سوخت اصلی پشت انواع نرم افزارهای تشخیص چهره است.
فناوری
این فناوری از راه اندازی اوکراینی به دست آمده Looksery ، برنامه ای است که به کاربران اجازه می دهد ویژگی های صورت خود را هنگام چت تصویری و عکس ها تغییر دهند. Snapchat این استارتاپ تغییر چهره مبتنی بر اودسا را در سپتامبر 2015 به قیمت 150 میلیون دلار خریداری کرد. طبق گزارشات ، این بزرگترین کسب فناوری در تاریخ اوکراین است.

فیلترهای واقعیت افزوده آنها به حوزه بزرگ و سریع رو به رشد بینایی رایانه وارد می شود. بینایی کامپیوتری را می توان نقطه مقابل گرافیک کامپیوتری دانست. در حالی که گرافیک کامپیوتری سعی در تولید مدل های تصویری از مدل های سه بعدی دارد ، بینایی رایانه سعی می کند از داده های تصویر یک فضای سه بعدی ایجاد کند. چشم انداز رایانه ای در جامعه ما بیش از پیش مورد استفاده قرار گرفته است. این است که چگونه چک های خود را اسکن می کنید و داده ها از خطوط استخراج می شوند. به این ترتیب می توانید چک ها را با تلفن خود واریز کنید. این است که چگونه فیس بوک می داند چه کسانی در عکس های شما هستند ، چگونه اتومبیل های خودران می توانند از برخورد با افراد جلوگیری کنند و چگونه می توانید بینی خود را دچار تردید کنید.
نحوه عملکرد فیلترهای Snapchat
Looksery معتقد است مهندسی آنها محرمانه است ، اما هر کس می تواند به اختراعات خود به صورت آنلاین دسترسی پیدا کند. ناحیه خاصی از Computer Vision که فیلترهای Snapchat از آن استفاده می کنند پردازش تصویر نامیده می شود. پردازش تصویر عبارت است از تبدیل یک تصویر با انجام عملیات ریاضی بر روی هر پیکسل روی تصویر ارائه شده.
1 - تشخیص چهره:
اولین مرحله به این صورت عمل می کند: با توجه به ورودی تصویر یا قاب ویدئویی ، تمام چهره های موجود انسان را بیابید و کادر محدود کننده آنها را (یعنی مستطیل به شکل: X ، Y ، عرض و ارتفاع) مختص کنید.
تشخیص چهره از زمان حل مشکل در اوایل دهه 2000 اما با چالش هایی از جمله تشخیص چهره های ریز ، جزئی و غیر پیشانی روبرو است. پرکاربردترین تکنیک ترکیبی از هیستوگرام گرادیانهای جهت دار (به اختصار HOG) و ماشین بردار پشتیبان (SVM) است که با توجه به کیفیت خوب تصویر نسبتهای متوسط نسبتاً خوبی را بدست می آورد اما این روش قادر به تشخیص زمان واقعی در حداقل در CPU.

اینجاست نحوه عملکرد آشکارساز HOG/SVM:
با توجه به تصویر ورودی ، نمای هرمی آن تصویر را که هرمی از نسخه کوچک شده چندگانه تصویر اصلی است محاسبه کنید. برای هر ورودی روی هرم ، از روش پنجره کشویی استفاده می شود. مفهوم پنجره کشویی بسیار ساده است. با حلقه زدن بر روی یک تصویر با اندازه گام ثابت ، تصاویر کوچک معمولاً وصله می کننداندازه 64 * 128 پیکسل در مقیاس های مختلف استخراج می شود. برای هر وصله ، الگوریتم تصمیم می گیرد که آیا دارای صورت است یا نه. HOG برای پنجره فعلی محاسبه می شود و به طبقه بندی SVM (خطی یا غیر) منتقل می شود تا تصمیم گیری انجام شود (یعنی صورت یا نه). هنگامی که با هرم انجام می شود ، معمولاً یک عملیات سرکوب غیر حداکثر (به اختصار NMS) به منظور دور انداختن مستطیل های انباشته انجام می شود. در اینجا می توانید اطلاعات بیشتری در مورد ترکیب HOG/SVM بخوانید.
2 - نشانه های صورت:
این مرحله بعدی در مرحله تجزیه و تحلیل ما است و به شرح زیر عمل می کند: برای هر صورت تشخیص داده شده ، مختصات ناحیه محلی را برای هر عضو یا ویژگی صورت آن صورت نمایش دهید. این شامل چشم ها ، استخوان ، لب ها ، بینی ، دهان ، ... مختصات معمولاً به شکل نقاط (X ، Y) است. یعنی تصویر بریده با صورت مورد نظر) ، اما اجرای آن برای برنامه نویس بسیار دشوار است مگر اینکه از تکنیک های نه چندان سریع یادگیری ماشین مانند آموزش و اجرای طبقه بندی استفاده شود.

می توانید در مورد استخراج نشانه های صورت در اینجا یا این PDF بیشتر بدانید: یک میلی ثانیه تراز صورت با مجموعه درختان رگرسیون در برخی موارد و بدیهی مفید ، تشخیص چهره و استخراج نشانه ها در یک عملیات واحد ترکیب می شوند.
3 - پردازش تصویر
اکنون که چهره شناسایی شده است ، Snapchat می تواند از پردازش تصویر استفاده کند برای اعمال ویژگی ها بر روی صورت کامل با این حال ، آنها تصمیم گرفتند یک قدم جلوتر بروند و می خواهند ویژگی های صورت شما را پیدا کنند. این کار با کمک مدل شکل فعال انجام می شود.
مدل شکل فعال یک مدل صورت است که توسط علامت گذاری دستی مرزهای ویژگی های صورت در صدها تا هزاران تصویر آموزش داده شده است. از طریق یادگیری ماشین ، یک "چهره متوسط" ایجاد می شود و این را با تصویری که ارائه می شود هماهنگ می کند. این چهره متوسط ، البته دقیقاً با چهره کاربر مطابقت ندارد (همه ما چهره های متنوعی داریم) ، بنابراین پس از تناسب صورت ، پیکسل هایی در اطراف لبه "متوسط چهره" مورد بررسی قرار می گیرند تا تفاوت در سایه زنی جستجو شود. به دلیل آموزش الگوریتم (فرایند یادگیری ماشین) ، دارای اسکلت اساسی در مورد ظاهر برخی از ویژگی های صورت است ، بنابراین به دنبال الگوی مشابه در تصویر داده شده است. حتی اگر برخی از تغییرات اولیه اشتباه باشند ، با در نظر گرفتن موقعیت سایر نقاطی که آن را ثابت کرده است ، الگوریتم خطاهایی را که مرتکب شده است تصور می کند که در آن فکر می کرد جنبه های خاصی از صورت شما وجود دارد. سپس مدل یک مش تنظیم می کند و یک مدل سه بعدی ایجاد می کند که می تواند با صورت شما تغییر حالت دهد.

این کل فرایند تشخیص چهره/ویژگی هنگامی انجام می شود که درست قبل از انتخاب فیلتر خود آن شبکه سفید را مشاهده کنید. سپس فیلترها با افزایش آنها یا افزودن چیزی در بالای آنها ، مناطق خاصی از صورت ارائه شده را مخدوش می کنند.
از فیلترها تا تعویض صورت
نسخه به روز شده Snapchat چند ماه قبل دارای قابلیت تعویض صورت با a بوددوست ، چه در زمان واقعی و چه با دسترسی به برخی از چهره های گالری خود. توجه کنید که چگونه صورت ها قابل مشاهده هستند ، این موقعیتی است که مدل آماری در آن قرار دارد. این به Snapchat کمک می کند تا شما و دوستانتان را سریع تر تراز کرده و ویژگی ها را عوض کند.
پس از قرار دادن همه ویژگی های خود ، برنامه مش ای در امتداد صورت شما ایجاد می کند که به هر نقطه فریم به فریم می چسبد. این مش اکنون می تواند همانطور که Snapchat احساس می کند ، ویرایش و اصلاح شود.

برخی از لنزها یا از شما می خواهند ابروهای خود را بالا بیاورید و یا با باز کردن دهان خود کارهای بیشتری انجام می دهند. فکر کردن درباره این نیز بسیار ساده است ، اما الزام به الگوریتم های بیشتری نیاز است.
همانطور که قبلاً ذکر شد ، این فناوری جدید نیست. اما برای انجام همه آن فرایندها در زمان واقعی و روی یک پلت فرم تلفن همراه ، قدرت پردازش زیادی همراه با برخی الگوریتم های پیچیده نیاز است. به همین دلیل اسنپ چت تصور کرد که بهتر است به جای ساختن بستر خود ، 150 میلیون دلار برای خرید Looksery بپردازید.
نتیجه گیری
امیدوارم این مطلب آموزنده باشد و مانند من کنجکاوی شما را تکان دهد. در حال حاضر ، من فیلترهای Snapchat را عمیق تر کاوش می کنم ، لنز صورت مورد علاقه خود را آزمایش می کنم ، از تمام دیدهای رایانه ای که در پشت صحنه اتفاق می افتد ، آگاهی و قدردانی می کنم.
- -
اگر از این قطعه لذت بردید ، اگر دکمه کف زدن را بزنید ، دوست دارم آن را دوست داشته باشید
پیشرفتهای اخیر در دید رایانه ای مدرن
پیشرفتهای اخیر در دید رایانه ای مدرن
بینایی رایانه ای فراتر از طبقه بندی اشیاء
در 50 سال گذشته ، کامپیوترها شمارش و طبقه بندی را یاد گرفته اند اما هنوز قادر به دیدن آن نیستند اکنون. امروزه ، از سال 2019 ، زمینه بینایی رایانه به سرعت در حال شکوفایی است و دارای پتانسیل وسیعی برای کاهش همه چیز از ناهماهنگی های مراقبت های بهداشتی تا محدودیت های حرکتی در مقیاس جهانی است.

در سال های اخیر ، ما موفقیت بزرگی را در Computer Vision که بر روی AlexNet یا معماری های مشابه CNN به عنوان ستون فقرات ساخته شده است ، مشاهده کرده ایم. درست است که این فرآیند از نظر نحوه یادگیری از مغز انسان الگوبرداری شده است. شبکه ای از واحدهای یادگیری به نام نورون یاد می گیرد که چگونه سیگنال های ورودی مانند تصویر یک خانه را به سیگنال های خروجی مربوطه مانند برچسب "خانه" تبدیل کند. برای کسب اطلاعات بیشتر در این مورد به وبلاگ قبلی من مراجعه کنید.
در 2-3 سال گذشته ، ما دستاوردهای بزرگی را در زمینه دیدهای مبتنی بر یادگیری عمیق فراتر از طبقه بندی شروع کرده ایم. من در این وبلاگ به چند مورد مهم از آنها اشاره کرده ام.
تشخیص شی
از بین چندین روش موجود ، 2 خانواده از تکنیک های تشخیص شی در 3-4 سال گذشته در بینایی رایانه ای مدرن-

دو مرحله ای: منطقه بر اساس پیشنهاد
R-CNN ، Fast-R-CNN ، Faster-R-CNN [Girshick et al. CVPR 2014]
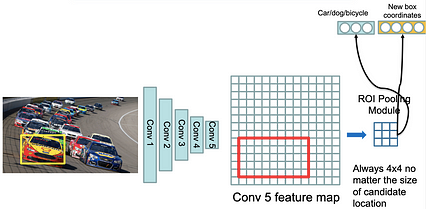
یک مرحله ای را استخراج می کند : YOLO ، SSD ، شبکیه چشم
تشخیص شی در اینجا به عنوان یک مشکل رگرسیون تنظیم شده است. یک شبکه عصبی واحد برای پیش بینی مستقیم کلاسها و لنگرهای جعبه ای بدون نیاز به مرحله دوم عملیات طبقه بندی هر پیشنهاد استفاده می شود. فضای خروجی با طراحی ؛ این مجموعه کوچک از جعبه ها
محدودیت های YOLO-
YOLO v3 : پیشرفت افزایشی
جوزف ردمون ، علی فرهادی- 2018
انتخاب بین یک مرحله در برابر m تشخیص مرحله آخر-
 عملکرد در MS-COCO
عملکرد در MS-COCO برای مقایسه کامل ، این مورد را بررسی کنید-جبران سرعت/دقت آشکارسازهای اجسام پیچشی مدرن ، جاناتان هوانگ و همکاران. al.، 2017
تقسیم بندی تصویر
پیکسل ها را به مناطق معنی دار یا مشابه ادراک گروه بندی کنید. شرکتهایی مانند Keymakr بهترین ابزار کلاس و خدمات کامل را برای تقسیم بندی پیچیده در فیلم و تصاویر ارائه می دهند.
 ماسک R-CNN ، Kaming He et. آل 2017 [ICCV 2017 Best Paper Award-Marr Prize]
ماسک R-CNN ، Kaming He et. آل 2017 [ICCV 2017 Best Paper Award-Marr Prize] Mask-R-CNN for Instance Segmentation

ردیابی عمیق
به زبان ساده ، قرار دادن یک شی در فریم های متوالی یک ویدیو ردیابی نامیده می شود.
ردیابی کلاسیک اشیاء انجام شده است با تکنیک هایی مانند - جریان نوری متراکم: این الگوریتم ها به برآورد بردار حرکت هر پیکسل در یک فریم ویدئویی کمک می کنند. جریان نوری پراکنده: این الگوریتم ها ، مانند ردیاب ویژگی Kanade-Lucas-Tomashi (KLT) ، مکان چند نقطه ویژگی در یک تصویر را ردیابی می کنند. فیلترینگ کالمن: یک الگوریتم بسیار معروف پردازش سیگنال است که برای پیش بینی موقعیت یک جسم متحرک بر اساس اطلاعات حرکت قبلی استفاده می شود. Meanshift و Camshift: این الگوریتم ها برای تعیین حداکثر تابع چگالی هستند. آنها همچنین برای ردیابی استفاده می شوند. روش های آنلاین گران هستند ، بنابراین باید مفروضات ساده تری را برای کارآیی کارها ایجاد کرد. چنین روشهای کلاسیکی گاهی اوقات به دلیل این واقعیت که ویژگیهای تصویر کلاسیک مانند گوشه هریس ، HOG یا SIFT همه در تغییرات مختلف ویژگیهای طبیعی تصویر شکسته می شوند ، شکست می خورند ، به عنوان مثال ، گوشه هریس نسبت به مقیاس تصویر آگنوستیک نیست.
اما به تازگی ، آثاری وجود دارد که تلاش کرده اند با استفاده از ویژگی های یادگیری عمیق ، نحوه ردیابی را مورد بررسی قرار دهند. • از آنجا که کارآیی کلیدی است ، یک استراتژی این است که از مجموعه بزرگی از فیلم های آفلاین با برچسب یاد بگیرید.
 D هلد ، S. Thrun و S. Savarese "آموزش ردیابی در 100 فریم بر ثانیه با شبکه های رگرسیون عمیق" ، ECCV 2016.
D هلد ، S. Thrun و S. Savarese "آموزش ردیابی در 100 فریم بر ثانیه با شبکه های رگرسیون عمیق" ، ECCV 2016. چگونه کار می کند- دو فرضیه: 1. شبکه فریم قبلی را با فریم فعلی مقایسه می کند تا پیدا شود شی هدف در فریم فعلی 2. این شبکه به عنوان یک "آشکارساز شیء" محلی و به سادگی عمل می کند نزدیکترین "شی" را پیدا می کند. پل وویگتلندر و همکاران al.، CVPR 2019
Networks Adversarial Networks
تنها 5 سال گذشته است و پیشرفت در هوش مصنوعی غیرقابل باور است. به ویژه این معماری GAN در سال 2019 ظاهر شد مانند BigGAN توسط Google و StyleGAN توسط NVIDIA قادر به ایجاد تصاویری دقیقا غیرقابل تشخیص از تصاویر واقعی هستند ، بنابراین مشاهده دیگر باورپذیر نیست.
 معماری ژنراتور مبتنی بر سبک برای شبکه های تولیدی خصمانه ، NVIDIA ، 2019
معماری ژنراتور مبتنی بر سبک برای شبکه های تولیدی خصمانه ، NVIDIA ، 2019 GAN از دو شبکه پی در پی تشکیل شده است-
یادگیری -
به خصوص در مورد StyleGAN ، که به جای تمرکز بر ایجاد تصاویر واقعی تر ، توانایی GAN ها را برای کنترل دقیق بر روی تصویر ایجاد شده بهبود می بخشد. در معماری و عملکردهای از دست رفته توسعه نمی یابد. در عوض ، یک سوئیت استاز تکنیک هایی که می تواند با هر GAN استفاده شود به شما امکان می دهد انواع کارهای جالب مانند ترکیب تصاویر ، تغییر جزئیات در سطوح مختلف و انجام نسخه پیشرفته تر انتقال سبک را انجام دهید. از تکنیک های موجود مانند عادی سازی نمونه های تطبیقی ، یک شبکه نقشه برداری برداری پنهان و یک ورودی یاد گرفته ثابت استفاده می کند.
 نمونه هایی برای StyleGAN
نمونه هایی برای StyleGAN تعجب نکنید که آیا کسی می گوید هیچ یک از تصاویر بالا واقعی نیست. این ابزارها توسط StyleGAN تولید می شوند. آموزش فناوری های بینایی کامپیوتری نه تنها آسان تر خواهد بود بلکه می تواند تصاویر را بهتر از الان تشخیص دهد. این نیز می تواند همراه با سایر فناوری ها یا زیر مجموعه های دیگر AI برای ایجاد برنامه های قوی تر استفاده شود. به عنوان مثال ، برنامه های زیرنویس تصویر را می توان با پردازش زبان طبیعی و تشخیص گفتار ترکیب کرد تا هوش بصری تعاملی شود. بینایی رایانه ای همچنین با ایجاد توانایی پردازش اطلاعات و حتی بهتر از سیستم بینایی انسان ، نقش بسزایی در توسعه هوش عمومی مصنوعی (AGI) و ابر هوش خواهد داشت.
مطالب جدید من را بخوانید مقاله در مورد فشرده سازی شبکه های عصبی عمیق بزرگ بدون آسیب رساندن به دقت-
https://medium.com/@ranjeet_thakur/pruning-deep-neural-network-56cae1ec5505