نظر
نظر
آیا شما ترجیح می دهید دانشمند داده NLP یا رایانه باشید؟
نگاهی دقیق تر به این نقش های معروف Data Scientist.
 عکس توسط JESHOOTS.COM در Unsplash [1].
عکس توسط JESHOOTS.COM در Unsplash [1]. فهرست مطالب
< oli> مقدمهمقدمه
هنگام درخواست موقعیت شغلی به عنوان دانشمند داده ، ممکن است انواع مهارت های مورد نیاز را در قسمت شرح شغل مشاهده کنید. شما پایین بروید و سپس ببینید تحصیلات مورد نیاز بین پست ها متفاوت است. مهمتر از همه ، شما یک نمای کلی می بینید که نقش را خلاصه می کند ، و اگرچه عنوان موقعیت یکسان است ، بخش به طور قابل توجهی متفاوت است. این تغییر به دلیل انواع مختلف موقعیت های علم داده موجود است. با این حال ، من متوجه شده ام که این نقش ها نام جدیدی به خود می گیرند زیرا شرکت ها تخصص خود را در علم داده درک می کنند. این دو شاخه محبوب علم داده عبارتند از پردازش زبان طبیعی (NLP) و دید رایانه ای. بسته به شرکتی که در نهایت قصد دارید در آن کار کنید یا در حال حاضر در آن کار می کنید ، برخی از موقعیت ها همچنان عنوان Data Science نامیده می شوند ، اما بر NLP یا Computer Vision تمرکز دارند ، در حالی که برخی از موقعیت ها به طور کلی علم داده است. من هم NLP و هم Computer Vision را برجسته می کنم تا بتوانید اطلاعات بیشتری در مورد معنای بودن هر کدام ، همراه با حقوق مورد انتظار ، و اینکه کدام نقش در نهایت تخصص بهتری برای شما است ، بیابید.
داده ها علم
علم داده یک اصطلاح بسیار گسترده است که اغلب بین مردم ، به ویژه در زمینه تکنولوژی مورد مناقشه است. دانشمندان داده فعلی می توانند نسبت به آنچه فکر می کنند علم داده بر اساس آنچه در اولین شغل خود تجربه کرده اند تعصب داشته باشند ، اما بعداً متوجه خواهند شد که علم داده در واقع یک اصطلاح کلی برای چندین رشته است. این رشته ها شامل پردازش زبان طبیعی ، دید رایانه ای ، یادگیری ماشین ، آمار ، ریاضیات ، برنامه نویسی ، تجزیه و تحلیل داده ها ، مدیریت محصول و هوش تجاری است. این واقعاً به شما و شرکتی که در آن کار می کنید بستگی دارد که تصمیم بگیرند از چه مسیر خاصی می خواهید بروید یا شاید در همه این جنبه ها کلی گرا باشید. از مزایای تخصص در NLP یا Computer Vision این است که می دانید در چه زمینه ای هستید و می توانید بر یادگیری و بهبود مهارت های خاص مورد نیاز هر موقعیت متمرکز شوید.
پردازش زبان طبیعی
گاهی از دانشمندان متخصص در NLP به عنوان مهندس NLP نیز یاد می شود. این تخصص بر زبان طبیعی انسانها و چگونگی مشارکت رایانه ها در هضم این ورودی بدون ساختار و سپس خروجی معنای ساختار یافته و مفید متمرکز است. در حالی که تعاریف و مثال های بی شماری از این نوع علم داده وجود دارد ، من می خواستم تجربه شخصی و در عین حال حرفه ای خود را با NLP ارائه دهم. من با سه نوع پروژه NLP کار کرده ام. این سه پروژه شامل موارد زیر است: به سایر اشکال NLP نیز. همه آنها ابزارها و کد مشابهی را برای ایجاد خروجی های مفید به اشتراک می گذارند. من به طور خاص بیشترین کار را با NLP در زبان برنامه نویسی پایتون انجام داده ام.
تجزیه و تحلیل احساسات - این فرم ازNLP بر خلق و خو ، احساسات ، قطبیت و موضوعیت یک متن معطوف می شود. یک جریان معمول کار برای تجزیه و تحلیل احساسات این است که داده های خود را جمع آوری کرده ، پیش پردازش کنید و سپس آن را نشانه گذاری کنید. اساساً ، در این مرحله ، شما هر کلمه ای را که در حال تجزیه و تحلیل ، تمیز کردن و حذف آن هستید خواهید داشت تا کلمات برچسب گذاری شوند. این قسمت بعدی معمولاً به عنوان برچسب گذاری POS یا Part-of-Speech شناخته می شود. هنگامی که نوع کلمات خود را مانند صفت ها ، اسم ها و افعال تعیین کردید ، می توانید به راحتی از عملکرد کتابخانه ای استفاده کنید که نمره قطبی را برای هر متن تعیین می کند. برخی از کتابخانه های NLP احساسی محبوب TextBlob و vaderSentiment هستند. من در اینجا زیاد عمیق نمی شوم ، اما اگر می خواهید مقاله ای در مورد ویژگی های NLP و این دو کتابخانه مشهور نوشته شود ، خوشحال می شوم این کار را انجام دهم (لطفاً در زیر نظر دهید). تجزیه و تحلیل احساسات می تواند به طور گسترده ای توسط اکثر مشاغل استفاده شود. در اینجا چند نمونه از مواردی که می توان تجزیه و تحلیل احساسات را اعمال کرد آورده شده است: بهبود محصول
در اینجا خلاصه ای از تجزیه و تحلیل احساسات آمده است:
جمع آوری داده ها
پیش پردازش
توکن
برچسب POS
نمره دهی
مدلسازی موضوع - این شکل از NLP تحت شاخه ای از یادگیری بدون نظارت است که به شما کمک می کند تا موضوعات اسناد متشکل از متن را بیابید. یکی از رایج ترین روش های یافتن موضوعات در یک سند ، استفاده از LDA یا Latent-Dirichlet-Allocation است. این یک تکنیک است که در نهایت موضوعاتی را که عبارات کلیدی محبوب و مهم را از متن شما خلاصه می کند ، نشان می دهد. در اینجا چند نمونه از مواردی که می توان از مدل سازی موضوعات استفاده کرد آورده شده است:
- ارائه موضوعات جدید از متن
- استفاده از این موضوعات برای تعیین برچسب های یادگیری تحت نظارت
< p> - بینش هایی که از جستجوی دستی بسیار دشوار استدسته بندی متن - این فرم از NLP یک تکنیک یادگیری تحت نظارت است که به طبقه بندی نمونه های جدید داده ها که نیازی به لزوماً فقط متن ندارند ، کمک می کند. اما حاوی مقادیر عددی نیز می باشد. گسترده تر از دو فرم NLP ، می توانید دسته بندی متن را به عنوان یک الگوریتم طبقه بندی معمولی در نظر بگیرید ، جایی که برچسب متن است و برخی از ویژگی ها نیز متن هستند. از همان تکنیک های بالا برای پیش پردازش ، تمیز کردن و استخراج معنی از متن استفاده خواهید کرد. در اینجا چند نمونه از مواردی که می توان طبقه بندی متن را اعمال کرد آورده شده است: p> محبوب ترین بسته پایتون nltk [2] است که مخفف Natural Language Toolkit است. شامل چندین کتابخانه است که در تلاش شما برای حل مشکلات با تکنیک های NLP ضروری هستند.
یک مهندس NLP چقدر درآمد دارد؟
بینایی رایانه ای
من معتقدم که این حوزه از علم داده حتی تخصصی تر از NLP است. Computer Vision به جای داده های عددی یا متنی بر داده های تصویری و تصویری تمرکز می کند. از نظر من ، رایانه چشم انداز خطرات بیشتری دارد زیرا می تواند در آن استفاده شودصنایع بیشتری که لزوماً به بینش وابسته نیستند ، اما نیاز به اقدامات امنیتی و ایمنی دارند تا به کار گرفته شوند. به این فکر کنید که چگونه تجزیه و تحلیل NLP و احساسات برای تجزیه و تحلیل خوشبختی بازبینی افراد مفید بوده است ، این بینش مفید و قدرتمند است ، اما به همان اندازه که بینایی رایانه می تواند مfulثر یا مضر باشد ، مفید نیست. من برخی از انواع Computer Vision را در زیر برجسته می کنم.
تشخیص چهره - هنگامی که تلفن خود را بر می دارید ، به احتمال زیاد یک ویژگی امنیتی دارید که چهره شما را تجزیه و تحلیل می کند تا ببیند آیا واقعاً شما در تلاش برای دسترسی به خود هستید تلفن. یک کتابخانه معروف پایتون که از پروژه هایی برای تشخیص چهره سود می برد ، به درستی به عنوان face_recognition نامیده می شود. تصاویری که با آنها کار می کنید و از صورت تشکیل شده اند به صورت یک ویژگی کدگذاری می شوند. بر اساس ویژگی های مشترک صورت ، می توانید چهره های فردی را با چهره های یکسان یا متفاوت مطابقت دهید (یا ندهید) تا در نهایت صورت را تشخیص دهید.
تشخیص شی - با استفاده از اطلاعات شیء ، این فرم رایانه می تواند در تشخیص اجسام کمک کند. OpenCV یک ابزار محبوب است که توسط برنامه نویسان و دانشمندان داده که مایل به تمرکز بر تشخیص اشیا هستند ، مورد استفاده قرار می گیرد.
شما می توانید نمونه هایی از دید کامپیوتر را در موارد زیر پیدا کنید:
- تشخیص تصویر
- شناسه چهره iPhone
- برچسب گذاری در فیس بوک
- تشخیص عابران پیاده و خودروهای تسلا
یک مهندس بینایی کامپیوتر چقدر درآمد دارد؟
در حالی که هر دو این حقوق زیاد است ، من شخصاً از آگهی های استخدام دیده ام که نه تنها مهندسان بینایی کامپیوتر بیش از متوسط حقوق گزارش شده ، بلکه مهندسان NLP نیز درآمد دارند. از آنجا که این دو نقش در علم داده بیش از پیش تخصصی می شوند ، معتقدم به همین دلیل می توانید انتظار داشته باشید که حقوق بالاتری داشته باشید.
خلاصه
 عکس توسط Annie Spratt در Unsplash [5].
عکس توسط Annie Spratt در Unsplash [5]. اکثر دانشمندان داده احتمالاً نوعی از NLP یا Computer Vision را مطالعه کرده اند ، خواه از دانشگاه باشد یا از آموزش آنلاین. هر دوی این نقش های تخصصی در علم داده بسیار مورد احترام هستند و می توانند به صنایع بی شماری سود ببرند. هنگام پاسخ به این س ‘ال که "ترجیح می دهید مهندس NLP باشید یا مهندس بینایی کامپیوتر؟" در نهایت به ترجیحات و اهداف شغلی شما بستگی دارد. به این فکر کنید که دوست دارید در چه نوع پروژه هایی کار کنید ، در کدام صنعت می خواهید کار کنید و دوست دارید با کدام شرکت مرتبط باشید. هر دوی این موضوعات در علم داده می تواند نتایج بسیار بالایی از کار شما به همراه داشته باشد ، بنابراین هر یک به شما یک تجربه انگیزشی می دهد.
امیدوارم این مقاله برای شما جالب و مفید بوده باشد. با خیال راحت در زیر تجربه خود به عنوان یک دانشمند داده عمومی ، مهندس NLP یا مهندس بینایی رایانه کامنت بگذارید.
از شما برای خواندن متشکرم!
منابع
[ 1] عکس توسط JESHOOTS.COM در Unsplash ، (2018)
[2] پروژه NLTK ، مجموعه ابزار زبان طبیعی ، (2020)
[3] Glassdoor، Inc.، NLP Engineer حقوق و دستمزد ، (2008–2020)
[4] Glassdoor، Inc.، Computer Vision Engineers Salaries، (2008–2020)
[5] عکس توسط Annie Spratt در Unsplash ، ( 2020)
محرک PCB انعطاف پذیر می تواند حرکت فلپینگ را به پروژه های شما اضافه کند
محرک PCB انعطاف پذیر می تواند حرکت فلپینگ را به پروژه های شما اضافه کند
وقتی پروژه شما نیاز به حرکت دارد ، به احتمال زیاد شما مستقیماً به سراغ موتور DC ، استپر یا سروو می روید. اگر خیال پرداز هستید ، حتی ممکن است چیزی عجیب و غریب مانند محرک خطی یا پنوماتیک را در نظر بگیرید. اما الکترومغناطیس ساده-که نیرویی است که باعث می شود هر موتور الکتریکی کار کند-نیز می تواند به طرق غیر معمول تری مانند محرک PCB انعطاف پذیر Carl Bugeja استفاده شود.

بوججا اخیراً با محرک PCB خطی خود ، که دارای سیم پیچ های الکترومغناطیسی در سطح خود بود و می توانست یک کشویی آهنربای دائمی را به عقب و جلو بکشد ، خبرساز شد. در امتداد PCB این بسیار برجسته است زیرا این یک روش ارزان برای افزودن حرکت خطی با گشتاور کم به یک ساختار است. محرک جدید PCB انعطاف پذیر وی به روشی بسیار مشابه عمل می کند و حتی به نظر می رسد از همان طرح PCB استفاده می کند. اما ، در این مورد ، آثار روی یک تخته قابل انعطاف چاپ می شود که دارای سفتی تقریباً یک خط کش پلاستیکی نازک است.
برخلاف طراحی خطی با آهنربای کشویی ، این دستگاه برای استفاده با آهنربای ثابت ثابت PCB انعطاف پذیر در نزدیکی آن آهن ربا قرار می گیرد ، اما بین این دو فاصله وجود دارد. هنگامی که سیم پیچ نزدیکترین آهنربا فعال می شود ، مغناطیسی می شود و PCB به سمت دائمی کشیده می شود. در طرح فعلی آن ، منجر به حرکت تکان دهنده می شود. ما کاملاً مطمئن نیستیم که در پروژه های خود از چه چیزی استفاده می کنید ، اما مطمئن هستیم که به چیزی خواهید رسید.

طبقه بندی ماهی چند کلاسه در تصاویر با استفاده از آموزش انتقال و کراس
طبقه بندی ماهی چند کلاسه در تصاویر با استفاده از آموزش انتقال و کراس

چگونه از یادگیری ماشینی با ماهی استفاده می کنید؟
نکته:
و این خلاصه ای از پروژه سنگفرش نانو درجه ماشین یادگیری ماشین Udacity است.
کد: پیوند به Github Repo.
نمای کلی
< p> تقریباً 50٪ از جهان برای منبع اصلی پروتئین خود به غذاهای دریایی وابسته هستند. و بیشترین عرضه ماهی با درجه بالا در جهان از منطقه غربی و اقیانوس آرام حاصل می شود که حدود 7 میلیارد دلار بازار را در اختیار دارد. با این حال ، ماهیگیری غیرقانونی همچنان تهدیدی برای اکوسیستم دریایی در این مناطق است زیرا ماهیگیران اغلب به صید بی رویه و صید گونه های حفاظت شده برای گردشگری در اعماق دریا مانند کوسه و لاک پشت می پردازند.بر اساس گزارش Fortune در مورد استفاده فعلی از هوش مصنوعی در صنعت ماهیگیری ، شرکت های بزرگ ماهیگیری مانند ماهیگیری Luen Thai گزارش می دهند که متصدیان ماهیگیری در منطقه اقیانوس آرام به طور معمول یک مشاهده گر فیزیکی را برای همراهی ماهیگیران 10 بار از 200 بار در سال می فرستند ، با این حال ، به دلیل وجود آن ، این کافی نیست هیچ کس برای کنترل آنچه در 190 سفر دیگر به ازای هر قایق در حال انجام است ، نظارت نمی کند.
برای مقابله با مشکل نظارت صحیح ، یک سازمان غیرانتفاعی جهانی که با مشکلات زیست محیطی مبارزه می کند تصمیم گرفته است با نصب راه حل فناوری ایجاد کند دستگاه های نظارت الکترونیکی مانند دوربین ، حسگرها و دستگاه های GPS برای ضبط کردن تمام فعالیت های موجود در هواپیما برای بررسی اینکه آیا آنها کار غیرقانونی انجام می دهند.

با این حال ، حتی اگر دسترسی به ساعتهای فیلم خام نیز مفید باشد ، طبق نظر TNC ، برای یک سفر طولانی 10 ساعته ، بررسی این فیلم به صورت دستی 6 ساعت برای بازبین ها طول می کشد. علاوه بر شرایط پر سر و صدا در یک قایق ماهیگیری ، شرایط آب و هوایی نامناسب مانند نور ناکافی ، برخورد قطرات باران به لنزهای دوربین و افرادی که مانع دیدن ماهی ها می شوند ، اغلب به انتخاب خود ، این کار را برای بازرسان انسان دشوارتر می کند.
< p> برای اتوماسیون این فرایند ، TNC با کاگل همکاری کرد تا از پزشکان یادگیری ماشین بخواهد سیستمی بسازند که به طور خودکار ماهی ها را از داده های فیلم فیلم با یک جایزه 150،000 دلاری شناسایی و طبقه بندی کند تا هزینه های آموزش شبکه عصبی عمیق پیوندی را جبران کند. مسابقه نظارت بر شیلات حفاظت از طبیعت توجه شرکت کنندگان را جلب کرده و در نشریاتی مانند Engadget ، Guardian و Fortune به نمایش در آمده است.هدف از این پروژه سنگفرش ساخت یک شبکه عصبی کانولوشن است که طبقه بندی های مختلف گونه های ماهی در حالی که تحت محدودیت های محاسبه به خوبی کار می کنند.
1.2. بیانیه مشکل
مجموعه داده های ماهی با شناسایی اشیا in موجود در تصویر مانند ماهی تن ، اوپا ، کوسه ، لاک پشت ، قایق های بدون ماهی روی عرشه و قایق هایی با ماهی های دیگر و طعمه های کوچک توسط TNC برچسب گذاری شد.
هدف پیش بینی احتمال وجود ماهی از یک کلاس خاص از کلاسهای ارائه شده است ، بنابراین از نظر یادگیری ماشین ، آن را به یک مشکل طبقه بندی چند طبقه تبدیل می کند.
هشت کلاس هدف ارائه شده است در این مجموعه داده: ماهی تن آلباکور ، تن بیگیه ، تن زرد ، ماهی ماهی ، اوپا ، کوسه ، سایر (به این معنی که ماهی در آن وجود دارد اما در گروه های فوق نیست) و ماهی بدون ماهی (به این معنی که ماهی در تصویر نیست).
هدف آموزش CNN است که بتواند ماهی ها را در این هشت کلاس طبقه بندی کند.
تکنیک های مبتنی بر یادگیری عمیق (CNN) در چند سال اخیر بسیار محبوب بوده است ، جایی که آنها به طور مداوم عملکرد بیشتری داشتند. رویکردهای سنتی برای استخراج ویژگی ها تا جایی که برنده چالش های imagenet هستند. در این پروژه ، از آموزش انتقال همراه با افزایش داده برای آموزش یک شبکه عصبی کانولوشن برای طبقه بندی تصاویر ماهیها به کلاسهای مربوطه استفاده خواهد شد.
آموزش انتقال به روند استفاده از وزنه های آموزش دیده اشاره دارد شبکه ها روی مجموعه داده های بزرگ از آنجا که شبکه های آموزش دیده قبلاً یاد گرفته اند که چگونه ویژگی های سطح پایین مانند لبه ها ، خطوط ، منحنی ها و غیره را با لایه های کانولوشن که اغلب از نظر محاسباتی بیشترین زمان برای فرآیند است شناسایی کنند ، استفاده از این وزن ها به شبکه کمک می کند تا به یک نمره خوب سریعتر از آموزش از ابتدا است. شرکت کنندگان در چالش های مشابه طبقه بندی تصویر در کاگل مانند رتینوپاتی دیابتی ، تشخیص نهنگ راست (که همچنین یک مجموعه داده دریایی است) نیز با موفقیت از یادگیری انتقال استفاده کرده اند.
برای آموزش موفقیت آمیز یک مدل CNN ، مجموعه داده نیاز دارد بزرگ بودن (که در اینجا مسلماً چنین نیست ، مجموعه داده ارائه شده از Kaggle بسیار کوچک است ، فقط 3777 تصویر برای آموزش) و ماشین آلات با قدرت محاسباتی بالاتر ، ترجیحا با GPU مورد نیاز است ، که در این قسمت به آنها دسترسی ندارم نقطه. خوشبختانه بسیاری از شبکه های این چنینی مانند RESNET ، Inception-V3 ، VGG-16 در چالش imagenet آموزش دیده برای استفاده عمومی در دسترس است و من از یکی از آنها VGG-16 استفاده می کنم که توسط گروه هندسه دیداری Oxford برای این مسابقه ایجاد شده است. نسخه دیگری از VGG وجود دارد ، یعنی VGG-19 با دقت بسیار مشابه ، با این حال استفاده از آن از نظر محاسباتی گران تر است بنابراین من از آن استفاده نمی کنم.
1.3. معیارها
معیار مورد استفاده برای این مسابقه کاگل ، از دست دادن لگاریتمی چند طبقه است (همچنین به عنوان آنتروپی مقطعی طبقه بندی شناخته می شود)

در اینجا هر تصویر با یک کلاس واقعی برچسب گذاری شده است و برای هر تصویر باید مجموعه ای از احتمالات پیش بینی شده ارسال شود.
N تعداد تصاویر موجود در مجموعه آزمون ، M تعداد برچسب های کلاس تصویر ، log لگاریتم طبیعی است ، Yij در صورت مشاهده به کلاس 1 و در غیر این صورت 0 و P (Yij) احتمال پیش بینی شده مربوط به مشاهده است به کلاس . احتمالات ارسالی برای یک تصویر داده شده لازم نیست که یک به یک جمع شوند زیرا قبل از امتیازدهی مجدداً مقیاس بندی می شوند (هر سطر به مجموع سطر تقسیم می شود). یک طبقه بندی کننده کامل از دست دادن ورود به سیستم 0. خواهد داشت.
ورود به سیستم چند کلاسه طبقه بندی کننده هایی را که از پیش بینی نادرست اطمینان دارند مجازات می کند. در معادله فوق ، اگر برچسب کلاس 1 باشد (نمونه مربوط به آن کلاس است) و احتمال پیش بینی شده نزدیک به 1 باشد (پیش بینی های طبقه بندی صحیح است) ، پس از آن از دست دادن واقعاً کم است زیرا log (x) → 0 x x 1 ، بنابراین این نمونه مقدار کمی ضرر دارداز دست دادن کل و اگر این امر برای هر نمونه اتفاق بیفتد (طبقه بندی کننده دقیق است) ، کل ضرر نیز به 0 نزدیک خواهد شد.
از طرف دیگر ، اگر برچسب کلاس 1 باشد (نمونه از آن است کلاس) و احتمال پیش بینی شده نزدیک به 0 است (طبقه بندی کننده از اشتباه خود اطمینان دارد) ، چون log (0) تعریف نشده است به آن نزدیک می شود ... بنابراین از نظر تئوری ضرر می تواند به بی نهایت نزدیک شود. به منظور جلوگیری از شدت عملکرد log ، احتمالات پیش بینی شده با حداکثر (دقیقه (p ، 1−10 ^ 15) ، 10 ^ 15) جایگزین می شوند.
به صورت گرافیکی [¹] ، با فرض مثال دوم متعلق به کلاس j و Yij = 1 است ، نشان داده شده است که وقتی احتمال پیش بینی شده به 0 نزدیک می شود ، ضرر می تواند بسیار زیاد باشد.

II. تجزیه و تحلیل
برای ایجاد مجموعه داده ، TNC چندین ساعت فیلم قایقرانی را جمع آوری کرد و سپس فیلم را به 5000 تصویر تقسیم کرد که شامل عکس های ماهی گرفته شده از زوایای مختلف است. با شناسایی اشیا in موجود در تصویر مانند ماهی تن برچسب گذاری شد ، کوسه ، لاک پشت ، قایق های بدون ماهی روی عرشه و قایق هایی با ماهی های طعمه ای کوچک دیگر.
این مجموعه داده شامل 8 کلاس مختلف ماهی است که از فیلم خام از دوازده قایق ماهیگیری مختلف در شرایط مختلف نور و فعالیت های مختلف ، با این وجود داده های مربوط به زندگی واقعی است ، بنابراین هر سیستم برای طبقه بندی ماهی باید قادر به مدیریت این نوع فیلم ها باشد. مجموعه آموزش شامل حدود 3777 تصویر دارای برچسب است و مجموعه آزمایش دارای 1000 تصویر است. تصاویر با ابعاد ثابت تضمین نمی شوند و عکس های ماهی از زوایای مختلف گرفته می شوند. تصاویر حاوی هیچ حاشیه ای نیستند.
هر تصویر فقط یک دسته ماهی دارد ، با این تفاوت که بعضی اوقات در تصاویر ماهی های بسیار کوچکی وجود دارد که از آنها به عنوان طعمه استفاده می شود. حفاظت از طبیعت همچنین با مهربانی تجسم برچسب ها را ارائه داده است ، زیرا تصاویر خام می تواند باعث تحریک بسیاری از افراد شود.

از آنجا که ورودی فقط تصاویر خام است (آرایه های 3 بعدی با ارتفاع x عرض x کانال برای رایانه ها) ، مهم است که برای طبقه بندی آنها در برچسب های ارائه شده ، پیش پردازش شود. با این وجود جزئیات دقیق پیش پردازش به انتخاب معماری ما برای استفاده از یادگیری انتقال بستگی دارد. هیستوگرام های رنگی به عنوان ویژگی از این تصاویر خام استخراج شده اند. کانال های رنگی در طبقه بندی تصویر می توان از هیستوگرام ها به عنوان بردار ویژگی استفاده کرد با این فرض که تصاویر مشابه توزیع رنگی مشابهی دارند.
در اینجا ما هیستوگرام های هر تصویر را در مجموعه آموزش محاسبه می کنیم و نتیجه را برای مشابه ترین ها می یابیم. تصویر از هیستوگرام ها با معیار فاصله اقلیدسی.
نتایج یک تصویر نمونه تصادفی انتخاب شده در زیر آورده شده است:

واضح است که تصاویر در برچسب ها مشابه هستند ، اما به نظر می رسد مشابه نیستند. اما هیستوگرام آنها کاملاً مشابه است.
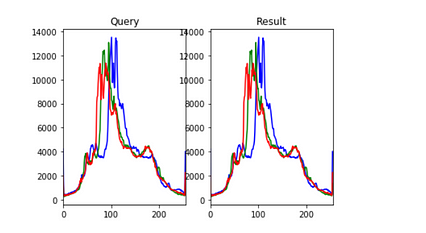
توجه داشته باشید که مدل معیار با نزدیکترین همسایگان k همچنین با نمودارهای رنگی به عنوان ویژگی آموزش داده می شود. با این وجود هیستوگرام ها ، شکل ، بافت و اطلاعات مکانی موجود در تصاویر را کاملاً نادیده می گیرند و نسبت به نویز بسیار حساس هستند ، بنابراین نمی توان از آنها برای آموزش یک مدل پیشرفته استفاده کرد.
2.3. الگوریتم ها و تکنیک ها
آموزش انتقال:
یادگیری انتقال اشاره داردبه فرآیند استفاده از وزنه ها ، یک شبکه آموزش دیده آموزش دیده روی یک مجموعه داده بزرگ که روی مجموعه داده دیگری اعمال می شود (یا به عنوان استخراج کننده ویژگی یا با راه اندازی مجدد شبکه). Finetuning به روند آموزش چند لایه یا چند لایه آخر شبکه آموزش دیده روی مجموعه داده جدید برای تنظیم وزن گفته می شود. یادگیری انتقال در عمل بسیار رایج است زیرا جمع آوری داده ها اغلب هزینه بر است و آموزش یک شبکه بزرگ از نظر محاسباتی گران است. در اینجا وزن های یک شبکه عصبی کانولوشن پیش آموزش داده شده روی مجموعه داده های imagenet برای طبقه بندی ماهی ها قابل اجرا است.
روش معیار:
معماری VGG (16):
برنده مسابقه ImageNet ILSVRC-2014 ، VGGNet توسط گروه هندسه تجسمی آکسفورد اختراع شده است ، معماری VGG کاملاً از لایه های کانولوشن 3 و 3 و حداکثر مخلوط سازی تشکیل شده است که در انتها یک بلوک کاملاً متصل است. مدل آموزش دیده در Caffe ، Torch ، Keras ، Tensorflow و بسیاری دیگر از کتابخانه های محبوب DL برای استفاده عمومی در دسترس است.
لایه ها:
توابع فعال سازی:
لایه های فعال سازی یک عملیات غیر خطی را برای خروجی اعمال می کنند سایر لایه ها مانند لایه های کانولوشن یا لایه های متراکم.
بهینه سازها:
افزایش داده: افزایش داده ها یک روش قاعده گذاری است که در آن ما تصاویر بیشتری را از داده های آموزشی تهیه می کنیم که با jitter تصادفی ، برش ، چرخش ، بازتاب ، مقیاس گذاری و غیره برای تغییر پیکسل در حالی که برچسب ها دست نخورده است ، ارائه می شود. CNN به طور کلی با داشتن داده های بیشتر عملکرد بهتری دارد زیرا مانع از نصب بیش از حد می شود.
نرمال سازی دسته ای: نرمال سازی دسته ای یک تکنیک است که اخیراً توسط Ioffe و Szegedy ساخته شده است و سعی می کند شبکه های عصبی را با مجبور کردن صریح فعالانه ها در سراسر شبکه به درستی تنظیم کند. در ابتدای آموزش توزیع واحد گوسی را بدست آورید. در عمل ما لایه های Batchnorm را درست بعد از لایه های متراکم یا کانولوشن قرار می دهیم. شبکه هایی که از نرمال سازی دسته ای استفاده می کنند نسبت به مقداردهی اولیه بد به طور قابل توجهی قوی تر هستند. از آنجا که نرمال سازی توانایی تعداد کمی از ورودی های خارج از کشور را برای تأثیر بیش از حد بر آموزش بسیار کاهش می دهد ، همچنین تمایل به کاهش تجهیزات اضافی دارد. بعلاوه ، نرمال سازی دسته ای را می توان به عنوان انجام پیش پردازش در هر لایه از شبکه تفسیر کرد ، اما در خود شبکه یکپارچه است.
2.4. معیار
انتخاب تصادفی: ما احتمال یکسانی را برای ماهی متعلق به هر کلاس از هشت کلاس برای معیار ساده لوح پیش بینی می کنیم. این ارسال 2.41669 از دست دادن ورود به سیستم در صفحه جدول Kaggle است.
طبقه بندی نزدیکترین همسایه K: یک مدل K-Nearest همسایه بر روی هیستوگرام رنگی تصاویر با فاصله اقلیدسی به عنوان متریک فاصله آموزش داده شد. این باعث کاهش 1.65074 ورود به سیستم در تابلوی امتیازات می شود.
یک شبکه عصبی کانولوشن کاملاً طراحی شده باید بتواند مدل پایه انتخاب تصادفی را به راحتی در نظر بگیرد ، حتی اگر مدل KNN به وضوح از معیار اولیه پیشی بگیرد. با این حال ، به دلیل هزینه های محاسباتی ، ممکن است امکان اجرای مدل یادگیری انتقال با معماری VGG-16 برای تعداد کافی دوره وجود نداشته باشد تا بتواند همگرایی داشته باشد.
بنابراین نمره مناسب برای ضرب و شتم معیار KNN چیزی کمتر از 1.65074 است حتی اگر اختلاف زیاد نباشد با توجه به اینکه شبکه عصبی طولانی تر کار می کند باعث کاهش ضرر خواهد شد.
III. روش
3.1 پیش پردازش
همانطور که در استفاده از VGG16NET مانند معماری برای یادگیری انتقال ، تصاویر پیش پردازش می شوند همانطور که در مقاله اصلی VGGNet انجام می شود. سازندگان VGGNet اصلی ابتدا میانگین هر کانال (R ، G ، B) را کم می کنند بنابراین داده های مربوط به هر کانال میانگین 0. بود.
علاوه بر این ، نرم افزار پردازش آنها انتظار داشت ورودی در (B ، G ، R) ترتیب دهید در حالیکه پایتون به طور پیش فرض انتظار دارد (R ، G ، B) ، بنابراین تصاویر باید از RGB -> BGR تبدیل شوند. در این مجموعه داده تصاویر ورودی نیز در اندازه ها و رزولوشن های مختلف ارائه می شوند ، بنابراین اندازه آنها به 150 150 150 3 3 تغییر یافت تا اندازه آنها کاهش یابد. داده داده شده توسط کاگل هیچ مجموعه اعتبارسنجی ندارد ، بنابراین به یک مجموعه آموزش و یک مجموعه اعتبار سنجی تقسیم می شود برای ارزیابی.
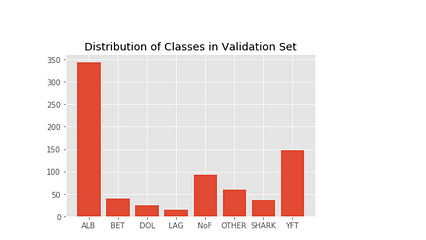
از 3777 تصویر ، 3019 تصویر در مجموعه آموزش و بقیه (0.8٪ از همه کلاس ها) در مجموعه اعتبار سنجی است. توجه داشته باشید که به جای استفاده از روش train_test_split در scikit-learn ، من به طور تصادفی 0.8٪ از هر کلاس را از مجموعه آموزش به مجموعه اعتبار سنجی با حفظ ساختار فهرست بردم. توزیع کلاسها را بصورت تصویری در زیر حفظ می کند.
Keras ImageDataGenerators از شاخه ها /آرایه های numpy به صورت دسته ای داده های آموزشی تولید می کند و آنها را با برچسب های خود پردازش می کند.داده های آموزش نیز در حین آموزش مدل تغییر داده شد ، در حالی که از داده های اعتبار سنجی برای بدست آوردن صحت اعتبار سنجی و افت اعتبار در حین آموزش استفاده شد.

3.2. اجرا
در ابتدا خط مقدماتی با انتخاب تصادفی و نزدیکترین همسایگان K برای مقایسه اجرا شد. پس از آن تصاویر به یک مجموعه آموزش و یک مجموعه اعتبار سنجی تقسیم شدند. عملیات پیش پردازش مانند کم کردن میانگین هر یک از کانال ها همانطور که قبلاً ذکر شد انجام شد و از معماری VGG-16 بدون آخرین لایه های کاملاً متصل برای استخراج ویژگی های کانولوشن از تصاویر پیش پردازش شده استفاده شد. نمودار معماری VGG16 بدون لایه کاملاً متصل در زیر آورده شده است.

در مورد ویژگی های استخراج شده (کدهای CNN) ابتدا یک مدل کاملاً متصل به کار گرفته شد اما متأسفانه نتیجه خوبی نداشت. پس از آن ، من سطح تخلیه و عادی سازی دسته ای را به لایه کاملاً متصل اعمال کردم که نزدیکترین معیار K را تا 17.50 شکست. در اینجا نمودار لایه متراکم همراه با ترک تحصیل و نرمال سازی دسته ای فعال شده است.

من در این پیشنهاد اشاره کردم که می خواهم یک مدل ماشین بردار پشتیبان را در ویژگی های استخراج شده CNN امتحان کنم ، اما بعداً به نظر می رسید که مدل های ضعیف تر و از آنجا که هدف پروژه ایجاد مدل یادگیری انتقال است ، بهتر است بیشتر روی آن تمرکز کنید. به همین دلیل است که قبل از استخراج ویژگی های کانولوشن برای یادگیری انتقال ، من یک مدل اساسی CNN ایجاد کردم تا پارامترها را آزمایش کنم.
3.3 اصلاح
برای جلوگیری از خودسرانه ، عادی سازی دسته ای را در مدل اعمال کردم با عادی سازی دسته ای لایه های میانی ، وزن زیادی در لایه های میانی ایجاد می کند ، بنابراین به همگرایی خوب کمک می کند. حتی در مدل با عادی سازی دسته ای که در برخی دوره ها فعال شده است ، دقت آموزش بسیار بالاتر از صحت اعتبار بود ، که تقریباً 100٪ دقیق است. از آنجا که مجموعه داده ها کوچک است (فقط 3777 تصویر آموزشی) ، مطمئناً منطقی است که مدل ما الگوها را حفظ می کند. برای غلبه بر این مشکل ، از داده ها استفاده شد. افزودن داده با استفاده از چرخش های تصادفی ، برش ، ورق زدن ، جابجایی ، برش و غیره دسته های آموزشی ما را تغییر می دهد.
در مجموعه داده خاص ، برداشت تصادفی معنی ندارد زیرا ماهی در مقایسه با کل عکس کوچک است و برش دادن عکس ها ممکن است شرایطی را ایجاد کند که مدل شروع به استنباط بیشتر عکس به عنوان کلاس "بدون ماهی" کند زیرا ماهی در هنگام افزایش داده ها از بین رفته است. ورق زدن عمودی نیز منطقی نیست زیرا دوربین در یک موقعیت ثابت قرار دارد و شرکت ها نمی توانند عکس های قایق ها را از بالا به پایین ثبت کنند. من چرخش تصادفی را اضافه کرده ام زیرا ممکن است دوربین از یک گوشه به گوشه دیگر حرکت کند تا یک منطقه وسیع را پوشش دهد. من هم چنین ورق زدن افقی و جابجایی تصادفی را به بالا و پایین و در کنار هم اضافه کرده ام زیرا احتمالاً همه این سناریوها وجود دارد.
متأسفانه به اندازه کافی مدل با افزایش داده از نظر محاسباتی گران است و در هر دوره حدود 1 ساعت طول می کشد دستگاه من ، بنابراین من این مدل را فقط برای 5 دوره آموزش داده ام (همانطور که یادگیری ترانسی است ما قبلاً دارای وزنه های از قبل آموزش دیده ایم) و صحت اعتبار نهایی 85٪ است. افت تابلوی امتیازات برای این مدل 1.19736 است که 12.02 درصد کاهش افت ورود به سیستم را نشان می دهد. اگر منمی تواند مدل افزوده داده را برای چند دوره دیگر آموزش دهد و احتمالاً نتایج بهتری هم خواهد داد.
IV. نتایج
برای هر آزمایش فقط بهترین مدل همراه با وزن آنها ذخیره شد (یک مدل فقط در هر دوره ذخیره می شود اگر دقت اعتبار بیشتری نسبت به دوره قبل نشان دهد)
برای یادآوری ، بهترین مدل تاکنون از تکنیک یادگیری انتقال همراه با افزایش داده ها و عادی سازی دسته ای برای جلوگیری از نصب بیش از حد استفاده می کند. برای استفاده از یادگیری انتقال ، من وزنه های پیش ساخته ای را برای معماری VGG-16 جمع آوری کرده ام که توسط گروه هندسی بصری آکسفورد ایجاد شده است (از این رو نام VGG) و از معماری مشابه فقط با جایگزینی لایه های کاملاً متصل شده با افت متفاوت و عادی سازی دسته ای استفاده کردم. به دلیل کمبود منابع محاسباتی مجبور شدم از ترک تحصیلات تهاجمی در مدلهایم استفاده کنم ، در غیر این صورت مدلها تمایل داشتند دستگاه من را هنگام کار خراب کنند.
من همه تصاویر را طبق دستورالعمل های معماری VGG16 از پیش پردازش کرده ام. برای مدل نهایی من از مدل پایه VGG16 به استثنای لایه های کاملاً متصل به همراه وزنه های پیش ساخته استفاده کردم ، یک لایه Dense جدید با ترک تحصیل و عادی سازی دسته ای در بالای آن برای پیش بینی تصاویر نهایی اضافه کردم. این مدل نزدیکترین معیار را با 46/27 درصد کاهش و مدل انتخابی تصادفی را با 50/45 درصد کاهش افت ورود به سیستم چند طبقه را شکست می دهد. جدولی با تمام آزمایشات انجام شده به همراه نتایج آنها در زیر آورده شده است.
 < /img>
< /img> مدل کاملاً متصل من بر روی ویژگیهای CNN فقط 3.10 امتیاز کسب کرد ، حتی اگر ساختاری مشابه مدل کاملاً متصل VGG-16 اصلی داشته باشد مگر با افت بیشتر. (فکر می کنم به این دلیل است که این مدل از افت تحصیلی بیش از حد استفاده کرده است) در نتیجه باعث از دست دادن اطلاعات می شود.)
مدل پایه کانولوشن نیز عملکرد مشابهی دارد و این دو بهبودی نسبت به خط پایه ندارند. خوشبختانه مدل نهایی در جدول امتیازات عملکرد مطلوبی داشت و من را به بالای 45٪ از شرکت کنندگان فرستاد ، که بهترین مدل من تاکنون است. از آنجا که این یک مسابقه طبقه بندی تصویر است که در آن دسته بندی ها به شدت از دسته های imagenet گرفته نمی شوند (به عنوان مثال گربه ها و سگ ها) ، و دامنه بسیار بدیع و کاربردی است ، من معتقدم که این یک امتیاز مناسب است.
برای تأیید اعتبار مدل من پیش بینی هایی را برای داده های اعتبار سنجی ایجاد کردم که دارای امتیاز دقت 84.82٪ و ضرر ورود به سیستم 1.0071 بود. ورود به سیستم رهبران 1.19 است ، بنابراین ضرر ورود به سیستم کاملاً نزدیک است. در داده های اعتبار سنجی از 758 تصویر ، 664 تصویر به طور دقیق طبقه بندی شده و 94 تصویر نادرست است. نمودار ماتریس سردرگمی (غیر عادی) پیش بینی های داده های اعتبار سنجی در زیر آورده شده است.

همانطور که از ماتریس سردرگمی دیده می شود ، این مدل به ترتیب به خوبی در پیش بینی کلاسهای ALB و YFT (Albacore Tuna و YellowFin Tuna) تبحر دارد ، احتمالاً به این دلیل که داده های آموزشی ارائه شده توسط خود Kaggle دارای عکسهای ALB و YFT بیشتر از کلاسهای دیگر. با این حال ، ممکن است که کاگل یک مجموعه داده نامتعادل ارائه دهد زیرا این انعکاس دقیق حجم ماهیان در آن منطقه دریایی است که ALB /YFT دارد ، هر دو ماهی ماهی بیشتری گرفتار می شوند ، در حالی که کوسه ها در معرض خطر هستند بنابراین کمتر گرفتار می شوند . با این وجود ، با وجود شناسایی ، 35 مدل کوسه از 36 کوسه موجود در مجموعه اعتبار ، به طور دقیق شناسایی می شوندآنها نادر هستند.
نمودار ماتریس سردرگمی عادی پیش بینی های مجموعه اعتبار در اینجا آورده شده است.

من همچنین برخی از برچسب های صحیح را به صورت تصادفی و برخی از برچسب های نادرست را به طور تصادفی پیش بینی کرده ام تا ببینم آیا الگویی در برچسب های نادرست /صحیح وجود دارد یا خیر. .
به طور تصادفی از برچسب های صحیح نمونه برداری شده است:

به طور تصادفی از برچسب های نادرست نمونه برداری شد:
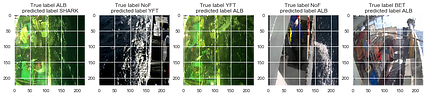
به نظر می رسد مدل پیش بینی شده ALB و YFT در بیشتر تصاویر نادرست که از طبقات غالب در مجموعه آموزش ارائه شده است. این نوع مشکلات احتمالاً می تواند با افزودن اطلاعات بیشتر برای سایر طبقات ، یا از طریق افزایش داده یا با جمع آوری مجدد فیلم های واقعی ، برطرف شود. کاگل به زودی قسمت 2 مسابقه شیلات را راه اندازی می کند ، جایی که احتمالاً داده های بیشتری در دسترس خواهد بود.
به نظر می رسد مدل در طبقه بندی بیشتر کلاس ها به غیر از BET و LAG که کلاسهایی هستند که کمترین میزان داده تصویر در آنها ارائه شده است. این مدل کاملاً مقاوم است زیرا عملکرد مشابهی در مجموعه داده های اعتبار سنجی و مجموعه داده های تابلوی امتیازات دارد. لازم به ذکر است که این مسابقه برخلاف اکثر مسابقات که امتیازات تابلوی امتیازات عمومی فقط برای زیرمجموعه ای از مجموعه داده های آزمون نشان داده می شود ، از تمام مجموعه داده های آزمون برای رهبران عمومی استفاده می کند.
به عنوان تقویت داده برای آموزش استفاده شد این مدل همچنین می تواند تغییرات اندکی را در تصاویر مانند تلنگر افقی ، نورهای مختلف ، چرخش ها و جابجایی به بالا و پایین که سناریوها هستند فیلم های واقعی فیلم در یک قایق در حال تکان دادن در یک اقیانوس کنترل کند.
در نمودار دقت و افت این مدل در هر دوره ، همچنین دیده می شود که دقت /افت آموزش با یک اعتبار سنجی در هر دوره (تولید مثل و مقایسه بیشتر آن در بخش تجسم فرم آزاد) همگراست. من حدود 6/5 ساعت این مدل را برای آموزش اجرا کردم که هر دوره حدود 1 ساعت طول می کشید.
با یک GPU خوب احتمالاً می توانم حداقل 90٪ دقت داشته باشم به سادگی مدل را برای چند دوره دیگر اجرا کنید.

نشت داده ها مسئله ای در این مسئله است زیرا بیشتر تصاویر بسیار شبیه به هم هستند زیرا فقط فریم های فیلم ها هستند. علاوه بر این ، تصاویر در اندازه های مختلف بودند و تصاویر در اندازه مشابه دارای برچسب های مشابه بودند (برای عکسبرداری از یک دوربین در همان زمان) ، برای غلبه بر این مسئله ، تغییر اندازه هر تصویر مهم بود. در هر صورت مجبور شدم برای تغذیه آنها در CNN اندازه آنها را تغییر دهم ، اما تغییر اندازه نیز برای جلوگیری از نشت اطلاعات مهم بود.
V نتیجه گیری
همانطور که دقت و افت مدل ها را در هر دوره ثبت کرده ام ، می توان مدل نهایی را با دومین گزینه بهترین مقایسه کرد. در اینجا نمودار دقت /افت مدل با نرمال سازی دسته ای ، اما بدون افزایش داده وجود دارد.

همانطور که می بینیم دقت آموزش در نمودار نزدیک به 100٪ است و از دست دادن آن نزدیک به 0 است. به همین ترتیب صحت اعتبارسنجی نیز نزدیک به 95٪ است در حالی که افت اعتبار حدود 0.2٪ نزدیک است پایان 10 دوره. ما همچنین روند کجا را می بینیماز دست دادن اعتبار در ابتدا کاهش می یابد اما بعد از حدود 2 دوره از دست دادن آموزش مدام کاهش می یابد /دقت بیشتر می شود ، در حالی که افت اعتبار به جای کاهش بیشتر می شود. واضح است که این مدل بیش از حد بر روی داده های آموزش است.
عملکرد این مدل ها در مجموعه آزمون در تابلوی امتیازات فقط 1.36175 است که از عملکرد مدل های آخر فقط در 5 دوره بدتر است. برای تجسم ، در اینجا نمودار دقت /زیان مدل نهایی در 5 دوره آمده است. ما می بینیم که دقت اعتبار سنجی بالاتر از دقت مدل باقی می ماند به دلیل ترک تحصیل تهاجمی و افزایش داده ها. منحنی اعتبار سنجی به احتمال زیاد به منحنی آموزش در تعداد کافی دوره تبدیل خواهد شد. این مدل نهایی حدود 1.19736 را در جدول رده بندی از دست داده است ، و مدل قبلی را 12.02٪ شکست داده و برای اولین بار مرا در 45٪ برتر جدول رده بندی قرار داده است.

5.2. انعکاس
برای دستیابی به این هدف برای حل نهایی ، سعی کرده ام به تدریج از مدل های پیچیده تری برای طبقه بندی تصاویر استفاده کنم. نزدیکترین همسایه K در روش هیستوگرامهای رنگی به عنوان پایه در Yelp Photo Classification Challenge مورد استفاده قرار گرفت ، اما آنها شباهت را با تصویر متوسط هر کلاس اندازه گیری کردند ، در حالی که من از نزدیکترین همسایه با اکثریت آرا استفاده کردم.
I " من حتی یک مدل پایه کانولوشن را به عنوان یک روش خوب امتحان کرده ام ، زیرا می خواستم ببینم که عملکرد مدل با مدل پیچیده فقط با چند لایه وجود دارد (متأسفانه عملکرد آن بسیار کم است).
در مرحله استفاده از داده افزایشی ، من مجبور شدم ابتدا ویژگی های CNN را استخراج کرده و با اجرای نسخه های مختلف لایه های بالایی روی ویژگی های CNN آزمایش کنم. فقط پس از استفاده از نرمال سازی دسته ای به جای مدل کاملاً متصل به سبک VGG ، پیشرفت چشمگیری دیدم و بنابراین از آن با معماری VGG استفاده کردم و با آن داده های داده ای را تقویت کردم.
حتی اگر کیفیت این مجموعه داده باشد بسیار بالا ، با توجه به اینکه داده های خام فیلم واقعی ماهیگیران در قایق ها را نشان می دهد ، من مطمئن نیستم که این مجموعه داده "نمایشی جامع" از داده های ماهیگیری است که سیستم در زندگی واقعی با آن روبرو می شود به دلیل تغییرات کوچک مانند آب و هوا تفاوت ها ، رنگ قایق ، ماهیگیران از ملیت متفاوت با پوشیدن لباس های مختلف قومی یا با رنگ پوست متفاوت می توانند به راحتی مدل را جبران کنند زیرا پس زمینه تغییر می کند.
من معتقدم رویکرد جعبه مرزی که قادر به تشخیص آن است ماهی های موجود در تصویر از طریق تشخیص جسم ، تصویر را برش دهید تا در ماهی بزرگ شود و سپس طبقه بندی کنید شانس بیشتری دارد. شاید ، قایق های ماهیگیری باید برخی از مناطق را در قایق های خود به عنوان یک نقطه مرجع برای طبقه بندی سریع تر ایجاد کنند.
سخت ترین قسمت برای من این بود که آزمایشات را روی دستگاه محلی خود اجرا کنم. زمان محاسبات بالاتر منجر به تعداد کمتری از آزمایش ها در مورد شبکه های عصبی ، به ویژه هنگامی که تازه می فهمم چه کاری باید انجام دهم زیرا اولین تجربه من با یادگیری عمیق است.
5.3. بهبود
با توجه به زمان و هزینه محاسباتی ، امکان اجرای آزمایشات بیشتر با استفاده از معماری های شناخته شده دیگر غیر از VGG-16 مانند RESNET و Inception V-3 برای این مجموعه داده وجود نداشت. قطعاً ممکن استکه معماری متفاوت موثرتر خواهد بود. یک رویکرد جعبه محدود که در آن ابتدا محل قرارگیری ماهی در قایق را پیدا می کنیم و سپس سعی می کنیم با بزرگنمایی ماهی ، آن را طبقه بندی کنیم ، می تواند دقت طبقه بندی را نیز بهبود بخشد. با توجه به وقت کافی و قدرت محاسباتی ، من قطعاً دوست دارم رویکردهای مختلف را بررسی کنم.
از آنجا که کلاس ها به شدت تعادل نداشتند ، یکی از فرضیه های من این است که اگر عکس های بیشتری را با افزایش داده برای کلاس هایی که تولید می کنم تولید کنم داده های کمتری نسبت به بقیه ، آنها را ذخیره کنید و برای هر کلاس به حدود 1000 تصویر برسید ، این مدل حتی قوی تر خواهد بود. من این بار این کار را انجام ندادم زیرا با کلاس 8 مجموعه آموزش حدود 8000 تصویر خواهد بود. با افزایش داده ها ، هر دوره با تنها 3777 تصویر آموزشی من را در لپ تاپ حدود 1 ساعت طول می کشد ، آموزش 8000 تصویر احتمالاً 2.5 برابر زمانی را که هر یک از دسته ها حتی با استفاده از Keras هنگام افزایش داده ها تغییر می کنند ، طول می کشد. ، که مدت زمان بیشتری طول می کشد.
مراجع:
ماهی در مقابل Zsh در مقابل باش و چرا باید به ماهی روی آورد
ماهی در مقابل Zsh در مقابل باش و چرا باید به ماهی روی آورد
دو نوع کاربر * nix وجود دارد: محتاط و ماجراجو
این یک واقعیت است ، اکثر توسعه دهندگان یونیکس و یونیکس مانند (مبتنی بر Linux) را دوست دارند سیستم عامل هایی مانند macOS ، اوبونتو و ... آنها پایدار ، قدرتمند ، بسیار قابل تنظیم هستند و از یونیکس شل قدرتمندی برخوردار هستند.
UNIX Shell چیست؟
پوسته یک پوسته است رابط کاربری با سیستم عامل اصلی این امکان را برای شما فراهم می کند تا با استفاده از متن و دستورات عملیات را انجام دهید و ویژگی های پیشرفته ای مانند امکان ایجاد اسکریپت را در اختیار کاربران قرار می دهد.
یونیکس شل ابزاری قدرتمند است که به برنامه نویسان امکان می دهد کارهای پیچیده را فقط با چند کلمه انجام دهند. . تعداد زیادی پوسته به طور گسترده در دسترس است مانند Bourne Shell ، C Shell و غیره.
من به ویژه از Bash ، Zsh و پوسته ماهی استفاده کرده ام و در اینجا نظرات من در مورد چرا روی آوردن به ماهی یا حتی Zsh ، یکی از بهترین کارهایی است که می توانید برای لذت بخشتر کردن برنامه نویسی خود انجام دهید.
یک دقیقه آشنایی با Bash ، Zsh و ماهی
Bash
< p> Bash رایج ترین پوسته لینوکس است. اگر یک ترمینال در Mac باز کنید (تا زمان macOS Mojave) ، یا اگر قبلاً از Linux استفاده کرده اید ، Bash را مشاهده کرده اید.این می تواند نام های مستعار ایجاد کند ، توابع ایجاد کند ، متغیرها را صادر کند و دستورات را اجرا کند ، درست مثل هر پوسته دیگر. علیرغم داشتن مجموعه محدودی از گزینه های قابل تنظیم ، به طور گسترده ای مورد استفاده قرار می گیرد و تعداد زیادی کاربر عادت به استفاده و ویژگی های خاص آن دارند.
Zsh
Zsh شبیه Bash و پوسته عالی دیگری است. سریعتر و قابل تنظیم تر از Bash است.
یکی از جالبترین موارد در مورد Zsh سفارشی سازی رنگ است. فقط با استفاده از چارچوبی به نام Oh My Zsh می توانید طرح زمینه و رنگ پوسته خود را تغییر دهید.
Zsh دارای بسیاری از ویژگی های مفید دیگر است ، از جمله تصحیح املا ، به اشتراک گذاری تاریخچه دستورات خود در چندین ترمینال ، نامگذاری میانبرهای دایرکتوری و غیره.
ماهی
ماهی یا "پوسته تعاملی دوستانه" ، به نظر من کاربرپسندترین و تعاملی ترین پوسته است.
بسیار قابل تنظیم تر از Zsh و Bash است. این یک تعداد ویژگی های جالب مانند نحو ثابت ، تکمیل زبانه زیبا و برجسته سازی نحو دارد ، انتخاب و استفاده از آن آسان است و از زمان اجرا بسیار خوبی برخوردار است.
شما می توانید تم و رنگ پوسته خود را فقط تغییر دهید با استفاده از چارچوبی به نام Oh My Fish. بر خلاف پوسته های فوق الذکر ، ماهی با POSIX سازگار نیست ، اما همچنین قصد ندارد.
می توانید اسکریپت های Bash را در دو زبان Zsh و ماهی اجرا کنید و خط shebang زیر را به خط اول خط خود اضافه کنید. پرونده باش.
#! /usr /bin /env bash
چه چیزی درباره ماهی ها ویژه است؟
 لوگوی Fish Shell
لوگوی Fish Shell قابل فهم و استفاده آسان
برخلاف پوسته های دیگر که برای تنظیمات زیادی نیاز دارند ماهی مطابق میل شما کار کند ، ماهی کاملاً خارج از جعبه کار می کند.
این کشتی دارای پرکاربردترین ویژگی هایی است که قبلاً در آن گنجانده شده است ، این ویژگی ها هنگام شروع استفاده بدون نیاز به نصب افزونه های اضافی وجود دارد. یا هر پرونده پیکربندی را نیشگون بگیرید ، مگر اینکه بخواهید. نحو آن ساده ، تمیز و سازگار است.
برجسته سازی نحو
برجسته سازی نحو ویژگی است که همه ما آرزو می کنیمCLI ما می تواند عملکرد داشته باشد. باعث صرفه جویی در وقت و ناامیدی می شود. خوب ، ماهی این کار را انجام می دهد ، و این کار را به خوبی انجام می دهد.
این به شما نشان می دهد قبل از اینکه حتی وارد enter شوید ، دستور شما یا فهرست مورد جستجو وجود دارد. قبل از اینکه وارد شوید ، می دانید که اشتباه تایپ می کنید یا نه. این امر تجزیه و تحلیل دستورات و یافتن خطاها را برای افراد راحت تر می کند.
(اکثر) خطاها را با رنگ قرمز برجسته می کند ، مانند دستورات غلط املایی ، گزینه های غلط املایی ، خواندن از فایل های موجود ، پرانتز و نقل قول های نامناسب ، و بسیاری از خطاهای رایج دیگر.
همچنین دارای برجسته سازی نقل قول ها و پرانتزهای منطبق است. اوه ، و بسیار زیبا و رنگارنگ است. این بسیاری از تم های سریع و پلاگین های جذاب بسیار زیبا را ارائه می دهد ، سبک ، عالی و آسان برای استفاده است.

همچنین ویژگی پیکربندی تحت وب را نیز ارائه می دهد. فقط تایپ کنید:
fish_config
در وب سایتی قرار خواهید گرفت که می توانید پوست پوسته خود را با آن شخصی سازی کنید.
 صفحه وب_پیکربندی ماهی
صفحه وب_پیکربندی ماهی تاریخچه جستجو به صورت درون خطی
این ویژگی تعاملی این پوسته است. شما شروع به تایپ کردن یک دستور می کنید و کلید بالا را فشار می دهید تا تمام زمانهای تاریخ Shell را ببینید که قبلاً از آن دستور استفاده کرده اید.
برای جستجوی تاریخچه ، به سادگی عبارت جستجو را تایپ کنید و کلید بالا را فشار دهید . با استفاده از پیکان بالا و پایین ، می توانید مسابقات قدیمی و جدید را جستجو کنید. تاریخچه ماهی به طور خودکار موارد تکراری را حذف می کند و زیرشاخه مطابقت برجسته می شود.
این ویژگی ها جستجو و استفاده مجدد از دستورات قبلی را بسیار سریعتر می کند.
پیشنهاد خودکار درون خطی
ماهی هنگام تایپ دستورات را نشان می دهد و پیشنهاد را در سمت راست نشانگر ، به رنگ خاکستری نشان می دهد. اگر یک دستور را اشتباه تایپ کنید ، با قرمز نشان داده می شود که این یک دستور نامعتبر است.
همچنین بر اساس سابقه و پرونده های معتبر موجود ، دستوراتی که بیشتر استفاده می شود را نشان می دهد و هنگام تایپ خودکار تکمیل می شود. .
 نمایش برای پیشنهاد خودکار درون خطی
نمایش برای پیشنهاد خودکار درون خطی تکمیل برگه با استفاده از داده های صفحه man
ماهی می تواند صفحات مرد ابزار CLI را در قالب های مختلف تجزیه کند. از طریق تمام تکمیلهای خودکار پیشنهادی ، یک دستور را وارد کرده و "برگه" را وارد کنید.
ماهی در عمل
در اینجا ، در ویدیوی نشان داده شده در زیر ، من کارهای زیر را در ماهی پوسته انجام داده ام:
 ماهی در عمل
ماهی در عمل 3. سپس سعی کردم به یک پوشه invalid_folder نامعتبر دسترسی پیدا کنم (توجه داشته باشید که نام پوشه قرمز رنگ است و این نشان می دهد که این پوشه وجود ندارد). سپس سعی کردم به یک پوشه معتبر دسترسی پیدا کنم.
موارد منفی استفاده از ماهی
خوب ، هیچ چیز عالی نیست ، و هرگز نباید باشد. از گسترش تاریخچه پشتیبانی کنید ("!!")
ماهی هیچ پشتیبانی نمی کند !! ، اما شما می توانید از چارچوب Oh My Fish Shell استفاده کنید و پلاگین thebang-bang را نصب کنید تا این میانبر را در پوسته ماهی داشته باشید. < /p>
کندتر از Bash
بیشتر ویژگی های ماهی راحتی را نسبت به سرعت اولویت می دهند. این یکی از دلایلی است که Bash برای نوشتن اسکریپت های Shell بهتر است.
در نتیجه گیری
ماهی پر از ویژگی های عالی است که بهره وری شما را در یک سطح متفاوت افزایش می دهد. بسیار مستند است و نصب آن نیز آسان است.
اگر در همه موارد بهترین نیست ، آن را ارائه می دهیددارای ویژگی هایی است که از فلسفه اساسی UNIX پیروی می کند:
اگر شما برنامه نویسی هستید که برای انجام کارها از ترمینال بسیار استفاده می کنید ، شما باید از شل فعلی خود خارج شده و از همین الان ماهی را شروع کنید.