پیشرفتهای اخیر در دید رایانه ای مدرن
پیشرفتهای اخیر در دید رایانه ای مدرن
بینایی رایانه ای فراتر از طبقه بندی اشیاء
در 50 سال گذشته ، کامپیوترها شمارش و طبقه بندی را یاد گرفته اند اما هنوز قادر به دیدن آن نیستند اکنون. امروزه ، از سال 2019 ، زمینه بینایی رایانه به سرعت در حال شکوفایی است و دارای پتانسیل وسیعی برای کاهش همه چیز از ناهماهنگی های مراقبت های بهداشتی تا محدودیت های حرکتی در مقیاس جهانی است.

در سال های اخیر ، ما موفقیت بزرگی را در Computer Vision که بر روی AlexNet یا معماری های مشابه CNN به عنوان ستون فقرات ساخته شده است ، مشاهده کرده ایم. درست است که این فرآیند از نظر نحوه یادگیری از مغز انسان الگوبرداری شده است. شبکه ای از واحدهای یادگیری به نام نورون یاد می گیرد که چگونه سیگنال های ورودی مانند تصویر یک خانه را به سیگنال های خروجی مربوطه مانند برچسب "خانه" تبدیل کند. برای کسب اطلاعات بیشتر در این مورد به وبلاگ قبلی من مراجعه کنید.
در 2-3 سال گذشته ، ما دستاوردهای بزرگی را در زمینه دیدهای مبتنی بر یادگیری عمیق فراتر از طبقه بندی شروع کرده ایم. من در این وبلاگ به چند مورد مهم از آنها اشاره کرده ام.
تشخیص شی
از بین چندین روش موجود ، 2 خانواده از تکنیک های تشخیص شی در 3-4 سال گذشته در بینایی رایانه ای مدرن-

دو مرحله ای: منطقه بر اساس پیشنهاد
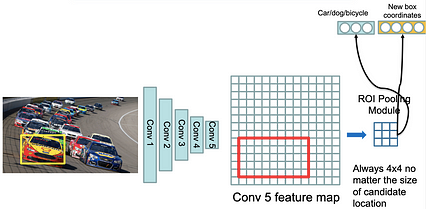
R-CNN ، Fast-R-CNN ، Faster-R-CNN [Girshick et al. CVPR 2014]
یک مرحله ای را استخراج می کند : YOLO ، SSD ، شبکیه چشم
تشخیص شی در اینجا به عنوان یک مشکل رگرسیون تنظیم شده است. یک شبکه عصبی واحد برای پیش بینی مستقیم کلاسها و لنگرهای جعبه ای بدون نیاز به مرحله دوم عملیات طبقه بندی هر پیشنهاد استفاده می شود. فضای خروجی با طراحی ؛ این مجموعه کوچک از جعبه ها
محدودیت های YOLO-
YOLO v3 : پیشرفت افزایشی
جوزف ردمون ، علی فرهادی- 2018
انتخاب بین یک مرحله در برابر m تشخیص مرحله آخر-
 عملکرد در MS-COCO
عملکرد در MS-COCO برای مقایسه کامل ، این مورد را بررسی کنید-جبران سرعت/دقت آشکارسازهای اجسام پیچشی مدرن ، جاناتان هوانگ و همکاران. al.، 2017
تقسیم بندی تصویر
پیکسل ها را به مناطق معنی دار یا مشابه ادراک گروه بندی کنید. شرکتهایی مانند Keymakr بهترین ابزار کلاس و خدمات کامل را برای تقسیم بندی پیچیده در فیلم و تصاویر ارائه می دهند.
 ماسک R-CNN ، Kaming He et. آل 2017 [ICCV 2017 Best Paper Award-Marr Prize]
ماسک R-CNN ، Kaming He et. آل 2017 [ICCV 2017 Best Paper Award-Marr Prize] Mask-R-CNN for Instance Segmentation

ردیابی عمیق
به زبان ساده ، قرار دادن یک شی در فریم های متوالی یک ویدیو ردیابی نامیده می شود.
ردیابی کلاسیک اشیاء انجام شده است با تکنیک هایی مانند - جریان نوری متراکم: این الگوریتم ها به برآورد بردار حرکت هر پیکسل در یک فریم ویدئویی کمک می کنند. جریان نوری پراکنده: این الگوریتم ها ، مانند ردیاب ویژگی Kanade-Lucas-Tomashi (KLT) ، مکان چند نقطه ویژگی در یک تصویر را ردیابی می کنند. فیلترینگ کالمن: یک الگوریتم بسیار معروف پردازش سیگنال است که برای پیش بینی موقعیت یک جسم متحرک بر اساس اطلاعات حرکت قبلی استفاده می شود. Meanshift و Camshift: این الگوریتم ها برای تعیین حداکثر تابع چگالی هستند. آنها همچنین برای ردیابی استفاده می شوند. روش های آنلاین گران هستند ، بنابراین باید مفروضات ساده تری را برای کارآیی کارها ایجاد کرد. چنین روشهای کلاسیکی گاهی اوقات به دلیل این واقعیت که ویژگیهای تصویر کلاسیک مانند گوشه هریس ، HOG یا SIFT همه در تغییرات مختلف ویژگیهای طبیعی تصویر شکسته می شوند ، شکست می خورند ، به عنوان مثال ، گوشه هریس نسبت به مقیاس تصویر آگنوستیک نیست.
اما به تازگی ، آثاری وجود دارد که تلاش کرده اند با استفاده از ویژگی های یادگیری عمیق ، نحوه ردیابی را مورد بررسی قرار دهند. • از آنجا که کارآیی کلیدی است ، یک استراتژی این است که از مجموعه بزرگی از فیلم های آفلاین با برچسب یاد بگیرید.
 D هلد ، S. Thrun و S. Savarese "آموزش ردیابی در 100 فریم بر ثانیه با شبکه های رگرسیون عمیق" ، ECCV 2016.
D هلد ، S. Thrun و S. Savarese "آموزش ردیابی در 100 فریم بر ثانیه با شبکه های رگرسیون عمیق" ، ECCV 2016. چگونه کار می کند- دو فرضیه: 1. شبکه فریم قبلی را با فریم فعلی مقایسه می کند تا پیدا شود شی هدف در فریم فعلی 2. این شبکه به عنوان یک "آشکارساز شیء" محلی و به سادگی عمل می کند نزدیکترین "شی" را پیدا می کند. پل وویگتلندر و همکاران al.، CVPR 2019
Networks Adversarial Networks
تنها 5 سال گذشته است و پیشرفت در هوش مصنوعی غیرقابل باور است. به ویژه این معماری GAN در سال 2019 ظاهر شد مانند BigGAN توسط Google و StyleGAN توسط NVIDIA قادر به ایجاد تصاویری دقیقا غیرقابل تشخیص از تصاویر واقعی هستند ، بنابراین مشاهده دیگر باورپذیر نیست.
 معماری ژنراتور مبتنی بر سبک برای شبکه های تولیدی خصمانه ، NVIDIA ، 2019
معماری ژنراتور مبتنی بر سبک برای شبکه های تولیدی خصمانه ، NVIDIA ، 2019 GAN از دو شبکه پی در پی تشکیل شده است-
یادگیری -
به خصوص در مورد StyleGAN ، که به جای تمرکز بر ایجاد تصاویر واقعی تر ، توانایی GAN ها را برای کنترل دقیق بر روی تصویر ایجاد شده بهبود می بخشد. در معماری و عملکردهای از دست رفته توسعه نمی یابد. در عوض ، یک سوئیت استاز تکنیک هایی که می تواند با هر GAN استفاده شود به شما امکان می دهد انواع کارهای جالب مانند ترکیب تصاویر ، تغییر جزئیات در سطوح مختلف و انجام نسخه پیشرفته تر انتقال سبک را انجام دهید. از تکنیک های موجود مانند عادی سازی نمونه های تطبیقی ، یک شبکه نقشه برداری برداری پنهان و یک ورودی یاد گرفته ثابت استفاده می کند.
 نمونه هایی برای StyleGAN
نمونه هایی برای StyleGAN تعجب نکنید که آیا کسی می گوید هیچ یک از تصاویر بالا واقعی نیست. این ابزارها توسط StyleGAN تولید می شوند. آموزش فناوری های بینایی کامپیوتری نه تنها آسان تر خواهد بود بلکه می تواند تصاویر را بهتر از الان تشخیص دهد. این نیز می تواند همراه با سایر فناوری ها یا زیر مجموعه های دیگر AI برای ایجاد برنامه های قوی تر استفاده شود. به عنوان مثال ، برنامه های زیرنویس تصویر را می توان با پردازش زبان طبیعی و تشخیص گفتار ترکیب کرد تا هوش بصری تعاملی شود. بینایی رایانه ای همچنین با ایجاد توانایی پردازش اطلاعات و حتی بهتر از سیستم بینایی انسان ، نقش بسزایی در توسعه هوش عمومی مصنوعی (AGI) و ابر هوش خواهد داشت.
مطالب جدید من را بخوانید مقاله در مورد فشرده سازی شبکه های عصبی عمیق بزرگ بدون آسیب رساندن به دقت-
https://medium.com/@ranjeet_thakur/pruning-deep-neural-network-56cae1ec5505


























